0 概述
0.1 问题
看了两本领域驱动设计(DDD)的书,Vernon的《领域驱动设计精髓》和《实现领域驱动设计》,一直不得要领。感觉领域驱动设计就像是脱裤子放屁的东西,啰嗦而没有必要。直到看到了知乎大神,阿莱克西斯,介绍的这本书《领域驱动设计模式、原理与实践》后,才真正明白到了领域驱动设计的意义。这本书可以说是给我打开了新世界的大门。
在阅读前我一直有几个大的困惑没有解决:
- 如何划分系统模块,让模块之间轻松加代码满足不断变化的需求。正常情况下,我们是设计好了以后,后期加需求就会遇到困难,一个需求需要改好几个地方的代码。要小心翼翼,如履薄冰。并且这样的代码,新来的人看起来会很头痛,因为理解这个模块的代码需要牵涉多个模块和需求。
- 如何让模块像乐高一样堆起来,可以动态地组合。例如一个库存模块,可以支持多种不同类型的销售单据。或者一个销售单据,如何支持多个不同的库存模块。
- 如何做单元测试,单元测试现在的做法是对外部依赖加mock,然后进行测试。但是mock的数量越多,测试就越脆弱,稍微的代码改动都会造成好几个单元测试重新改。更理想的情况是,mock的数量小,同时单元测试的覆盖率也高。
- 如何做多表的查询。对于涉及多个模块的数据的筛选和查询功能,我的方法是在每个模块筛选后,组合结果,然后通过getBatch来组合数据,但是这样的性能很差。但是,当这些逻辑放在数据库来做的话,感觉各个模块的数据就会泄漏到数据库上。每个模块的功能就不再是内聚的,它可能会涉及多模块的数据。
- 面向对象编程模式的意义在那里。编程的时候,我既需要考虑数据库的表结构应该如何涉及,也要考虑业务模块如何划分,写逻辑的时候全部都是过程式代码。找不到OOP编程的意义在哪里,感觉OOP是多此一举。
- 事务问题一直依赖于数据库的串行化隔离级别,因为一个命令,可能涉及多次的表操作,我们要保证写入的原子性。另一方面,要考虑并发情况下产生的数据竞争的问题。串行化的并发性能很低,但能保证结果一旦可靠和准确。如何在更好的并发性能下,实现原子性和隔离性。显然,在分布式环境下,我们更没有串行化隔离的级别,那么我们如何实现原子性和隔离性。
从建模,开发,测试,数据事务,这些问题一直困惑着我,使我没有往分布式的方向往前走。直到看到了这本书,这上面的大部分问题都得到了答案。而且令人惊讶的是,答案不是通过技术来实现的,而是跳出了技术的思维,用业务的角度去考虑问题。
0.2 启发
这真是让人拍案叫绝,也让人想起了芒格的一句话:
如果你手里拿的是锤子,那你看到的都是钉子。
如果你是一个擅长技术的人,你就会将所有的问题都尝试用技术的方法来解决它,也没有考虑其他方法。而现实世界不是这样的,每个问题的背后,其实你可以用不同的角度和方法来解决它。我们要做的是,综合多个方法的成本和结果,去选择最好的方法。而不是永远都在一个角度,一个方法上思考问题,这是非常悲哀的。
与此同时,DDD教会了一个重要方法论,永远要抓住核心是什么。只有抓住核心矛盾才能解决问题,而不是要去尝试解决所有矛盾。当找出了核心矛盾以后,要将绝大部分的资源都投入到解决核心矛盾上。而不是尝试为所有矛盾都分配平等的时间和资源。从这个角度看,木桶原理是不准确的,一个项目的成功与否不是与项目最薄弱的地方决定的,而是由项目最核心价值是否实现来决定的。
这两点启发可谓是对我打脸得啪啪响,我几乎踩中了这两个大坑而不自知。
0.3 核心理论
DDD是一个非常庞大的理论,看前两本的时候,我也曾被众多的术语和细节中淹没,而找不到它的要点在哪里。所以,先站在我的角度,描述一下它的核心理论
- 业务划分模块
- 公共语言UL
- 三步流程
0.4 业务划分模块
DDD使用子域来对问题域进行分解,然后对每个问题域采取单个上下文来划分。子域可以分为核心域,支持域和通用域,只有核心域我们才值得投入最好的资源去建模和实现。对模块的划分有两个准则:
- 以问题域,业务用例为核心。单个模块内部应该是逻辑自洽的,独立自治的。不同模块之间是逻辑关联尽可能少的。
- 以实用主义为判断标准。划分模块是为了让问题域更小,更容易去建模,因为越小的问题域就越容易建模。但是,过度地以分割模块,甚至建立不必要的抽象,属性和方法,建模的复杂性变大,而另外一方面,这样的建模如果对问题域没有帮助,我们就会严厉拒绝,即使分割的模块更小,更符合现实世界。所以,建模是否过度复杂的判断标准是,它是否对降低问题域复杂度有帮助,没有帮助的话就是过度建模。
这些话听起来都像是废话,但我们常常会违反以上的原则
0.4.1 现实世界划分模块
反例是以现实世界为基础划分模块。例如,食谱有标题和步骤的详细信息,也有排行榜需要的热度信息。所以,我们想当然地这样建模:
type Recipe struct{
RecipeId int
Title string
Steps []RecipeStep
LikeNum int
CollectNum int
VisitNum int
HotNum int
}但是,用户编辑食谱,和展示食谱排行榜其实是两个不同的业务,他们之间是很少很少互动的。用户编辑食谱时不需要查询排行榜的信息,食谱是否受欢迎也不是完全取决于食谱的标题,更多是取决于有多少人去阅读,点赞和收藏食谱。
两个不同业务的信息仅仅是因为他们在物理上是在一起的,所以就放在了一起,会让食谱实体过大,难以维护。
type Recipe struct{
RecipeId int
Title string
Steps []RecipeStep
}
type RecipeRank struct{
LikeNum int
CollectNum int
VisitNum int
}所以,更好的建模是让两个业务切分开,各自维护代码更加简单。
0.4.2 以名字划分模块
另外一个反例是,将不同的名字的实体划分到不同的模块,相同名字的实体放到同一个模块。就像书上的例子,电商中的产品,有三个部门需要,展示产品,库存产品,订单产品,物流产品,他们在物理上都是同一个产品,而且也是相同的名字——产品。
然后我们想当然地这样建模:
type Product struct{
ProductId int
Title string
//是否上架,展示产品用
IsOnShelf bool
//库存数量,库存产品用
StockCount int
//下单价格,订单产品用
OrderPrice int
//支持的物流方式,物流产品用
ExpressType int
}这样建模的结果是,产品实体非常忙,任意一个模块改代码都要找他,它就是一个超级模块,而且看代码也很累,经常牵一发而动全身。
更好的方法是,虽然产品都是同一个名字,但它在不同的业务环境下有不同的角色,所以应该分配不同的业务实体,每个部门下都应该有一个自己的产品实体。
//展示产品
type ListProduct struct{
ProductId int
Title string
//是否上架,展示产品用
IsOnShelf bool
}
//库存产品
type StockProduct struct{
ProductId int
Title string
//库存数量,库存产品用
StockCount int
}
//订单产品
type OrderProduct struct{
ProductId int
Title string
//下单价格,订单产品用
OrderPrice int
}但需求变化的时候,修改的时候自己模块的Product,而不需要全局Product的协助,这样能更快迭代,更松散的模块耦合。
0.4.3 过度抽象
开发者容易迷信于新技术,迷信于抽象工具,而忽略了抽象带来的代价与意义。常见的抽象误区是:
- 可视化流程配置,鼓吹lower code或者no code
- 规则引擎
- 盲目的业务中台
无论是用代码表达业务,还是用可视化引擎表达业务,降低仅仅是业务之间的关联规则而已。业务自身的复杂度还是没变,该写if/else的地方,换了可视化引擎仍然需要写if/else。而且,抽象自身也有很大的代价,全新工具的学习曲线与资源投入,缺少生态支持,自身系统是否成熟,是否支持高并发或者灵活的功能,是否支持单元测试和在线调试,这些都是不可忽略的因素。
第二个例子是,虽然理论上,用正则表达式可以对所有的字符串进行校验工作,为什么我们仍然去写if/else的字段校验呢。正则表达式作为字符串校验的抽象工具的确很成功,但是它没有具体业务的抽象性,它要支持任意字符串的校验,就要求了它的设计必须灵活以适应各种各样场景,这直接造成正则语言自身代码很不直观,学习曲线也很陡峭,写代码和看代码的人很累。
最后一个例子是,盲目追求大一统的业务抽象会产生比各自写代码更难维护。在最强调业务中台技术的阿里巴巴,天猫,盒马和闲鱼却是有各自的一套订单系统,而不是尝试用一个大一统的订单系统去处理所有的订单类型。因为,业务本来就是不同的,它们的个性远远多于共性。强行抽象出一套订单系统,只会让这个大一统的订单系统加入很多if/else来处理各自系统的订单逻辑。代码丑陋,而且难以理解和维护。
所以,使用抽象工具的方法应该是,仅当我们看到了多个业务逻辑都不断地重复某些代码时,我们才将这些代码单独拉出来,放在一个地方,形成抽象。
0.5 公共语言UL
DDD中的另外一个工具是公共语言UL。我们平常写代码的流程是这样的:
产品需求->写代码开发者为了实现需求,在脑海中建立模型,然后直接写代码。当需求变动后,代码由于没有提前考虑这些情况,而开始变得丑陋和难以维护。
所以,DDD的解决方法是:
产品需求->业务专家生成UL->写代码UL指出了为了实现需求,所以建立那些术语表,并指出每个实体应该有的属性和职责。建立以后,用业务用例来测试模型是否合理,不合理的话继续迭代模型。有了UL作为工具建立模型后,写代码就变得简单了,它仅仅是模型的翻译而已。
UL是DDD中比较费解和理想化的做法,我比较怀疑它在实际使用中的效果。当然,也可能是我还没理解透彻。
0.6 三步流程
1.获取A表的数据
2.执行一段业务逻辑
3.继续获取A表的数据
4.执行另外一段业务逻辑
5.查询其他模块(ao)的接口
6.执行另外一段业务逻辑
7.写入到A表的数据写代码时,不仅需要考虑业务复杂性,还要考虑技术复杂性,所以我们常常会写了以上的伪代码。对其他模块的调用,对数据库或者存储库的调用,业务复杂度也是相互交叉进行的。这样不仅难以维护,而且难以单元测试,需要很多的外部mock。
func do_logic1(){
do_logic1_1();
开启事务
do_logic1_2();
do_logic1_3();
提交事务
}
func do_logic1_1(){
查询其他模块(ao)的接口
}
func do_logic1_2(){
1.在存储库根据id获取一个聚合根
2.在内存上对聚合根进行修改
3.在这个聚合跟写入到存储库中
}
func do_logic1_3(){
1.在存储库根据id获取一个聚合根
2.在内存上对聚合根进行修改
3.在这个聚合跟写入到存储库中
}DDD规范了写代码应该遵循一个三步流程,对多个事务的操作,改为对多个聚合根的操作。而对聚合根的操作总是按照三步来执行
- 在存储库上获取这个聚合根,并加载内存上
- 在内存上修改聚合根
- 将内存上的聚合根保存到存储库上
第一和第三步是仅与技术复杂度相关的,第二步是仅与业务复杂度相关的。因此,我们可以在代码中隔离技术复杂度和业务复杂度的代码。技术复杂度的代码都在存储库上,而业务复杂度的代码就用简单的内存状态对象来实现。简单的内存状态对象不能写入数据库,也不能写入文件,它只能是一个内存状态的修改或查询操作而已。因为,这个简单的内存状态对象非常容易地被单元测试。而这个简单的内存状态对象,在DDD中称为领域对象,它是表达领域逻辑,也就是业务逻辑的地方。
type UserAccount struct{
UserId int
Account Money
}
func (this *UserAccount) Deposit(money Money){
this.Account = this.Account.Add(money)
}
func (this *UserAccount) Draw(money Money){
this.Account = this.Account.Sub(money)
if this.Account.Sign() < 0{
Throw(1,“你的账号不能透支”)
}
}
func Transfer(fromAccountId int,toAccountId int,money Money){
//从存储库中读取实体,或者聚合根
fromAccount := UserAccountRepo.Get(fromAccountId)
toAccount := UserAccountRepo.Get(toAccountId)
//在内存上修改聚合根
fromAccount.Draw(money)
toAccount.Deposit(money)
//将内存上的实体,或者聚合根保存到存储库上
UserAccountRepo.Save(fromAccount)
UserAccountRepo.Save(toAccount)
}例如,在一个转账服务中,UserAccount就是领域对象,而UserAccountRepo就是存储库。无论一个多么复杂的逻辑,我们都要转换为三步流程来实现。UserAccount是简单的内存状态对象,可以在不需要数据库的支持下执行单元测试,简单可靠,不需要mock。
那么,怎么编排与其他模块的交互。你有两个方法:
- 在应用服务中编排,就像例子中的do_logic1对三个子方法的调用,这是一种同步方法。
- 通过领域事件来交互,这是一种异步方法,可靠,反应快,但没有返回值。
具体使用哪个方法,要看不同的业务场景。
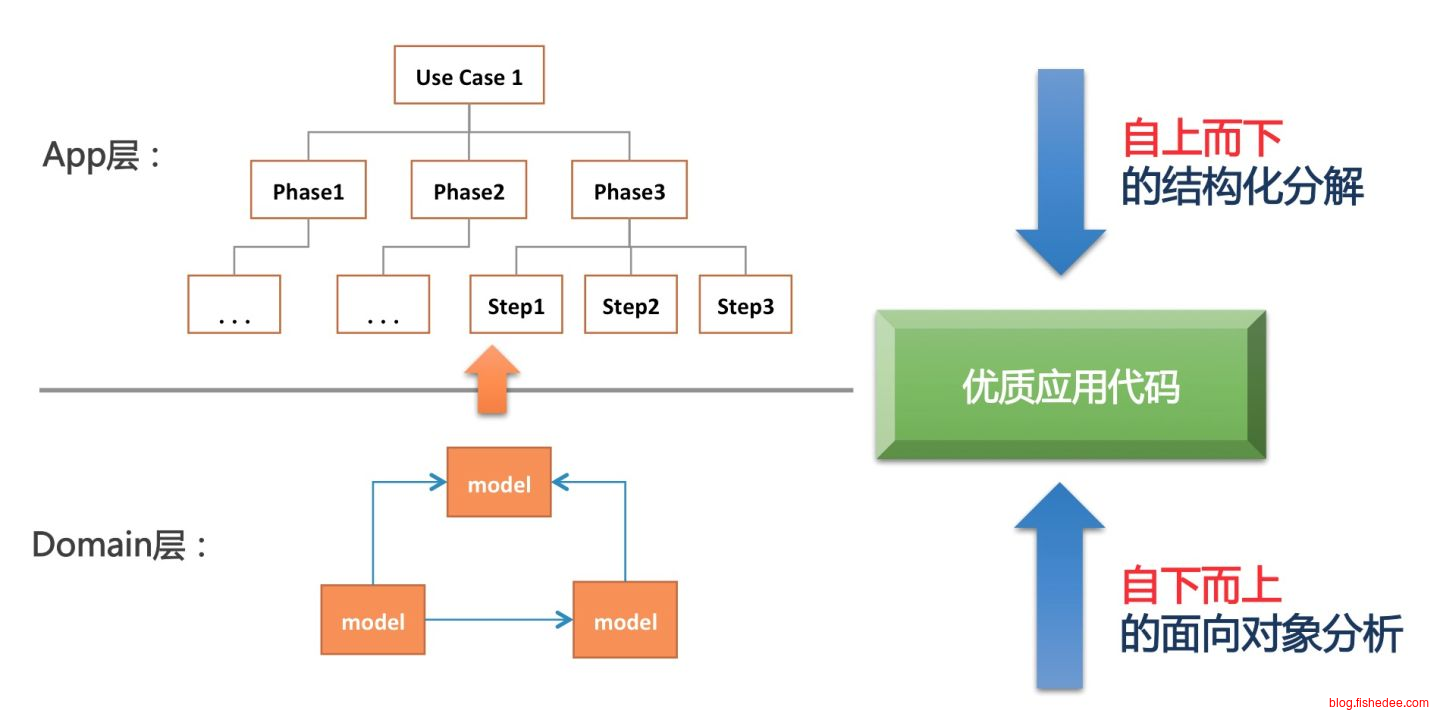
最后,我们得出了这个图,所有的业务逻辑都可以理论上按照这个方法来写。顶层是按照面向过程的方法,从上而下的,在应用服务层实现的,它负责编排领域对象,存储库,其他模块的同步调用。
底层是按照面向对象的方法,从下而上的,在领域对象层实现的,它仅实现领域逻辑,不能调用数据库,不能读写文件,不能同步调用其他模块,不能包含任何的技术复杂性的代码,仅仅是用来实现业务复杂性的。DDD推荐了一套实现工具,实体,值对象,聚合根,工厂方法。你可以不用这些工具,但这一层的原则不能违反。
1 什么是领域驱动设计
1.1 问题
复杂问题创建软件的挑战:
- 复杂度高,技术复杂性与领域逻辑复杂性界限不清,一起加大了系统的复杂性
- 难以沟通,开发与业务之间缺少相互沟通的桥梁,技术人员生成的模型难以适应不断发展的业务需求
- 大泥球,业务之间没有清晰的边界,一团混乱,写代码时牵一发而动全身,难以维护。
根据问题,DDD提出从战略模式与战术模式两个方面来解决
1.2 战略模式
- 对问题域进行分解,并从战略层面选择最核心的问题域,投入最好的资源去维护和实现它。
- 每个问题域用一个解空间去实现,而不是尝试用一个解空间去解决所有的问题域。这个解空间称为有界上下文。
- 公共语言UL来帮助建模协作。业务与开发之间使用公共语言来协作建模,建模的行为是双向的,而不是单向的。
- 有界上下文边界,每个有界上下文有自己独立的数据库,代码库,部署环境。有界上下文之间需要通过显式的边界进行交流,例如是RPC通信,事件通知,禁止直接修改其他上下文的数据库。
1.3 战术模式
- 实体对象,值对象,构成领域对象的基本单元。聚合根是一组有事务一致性要求的领域对象组合。领域服务是无状态的领域对象,它描述的是领域里面怎样做,如何做的概念,它没有任何字段,也没有副作用。
- 工厂是封装了领域对象创建的模式。事件是聚合根之间通信的方式。
- 存储库,是聚合根持久化的方式,它封装了技术复杂性。
2 提炼问题域
2.1 理解目标
提炼问题域的第一步是,思考为什么要创建系统。它的愿景,意图是什么。我们甚至可以创造影响力地图,根据目标,写出可以实现目标的各种方法,然后评价各种方法对实现目标的影响力有多少。最后,才决定什么才是业务最重要的,最核心的部分
2.2 建模协作
建模协作的方法为:
- 使用公共语言,创建一份术语表
- 与领域专家一起建模
- 使用事件风暴,CRC卡做粗建模。事件风暴主要关注,命令,实体与事件。CRC卡关注实体名称和职责。有了粗建模以后,我们才用UML做精建模
- 使用需求用例来测试模型是否准确
3 专注于核心领域
问题域通过分析,可以划分为多个子域。然后我们根据子域对项目目标的关系的,我们可以进一步区分子域的不同角色:
- 核心域,交付软件要实现的核心价值,也是该软件的根本竞争优势。它需要最好的资源来投入,最优质的人才,最细致的建模方式。例如,电商系统的,订单系统,支付系统和物流系统。
- 支撑域,这些子域不是业务的核心,但是做得好可以提高竞争优势,适合少量投入。例如,电商系统,商品名录和展示系统,买家和卖家系统。
- 通用域,这些子域不是业务的核心,做得好也不会产生竞争优势。那么最适合就是将这部分外包出去,找现有的解决方案来实现它。例如,电商系统的,电子邮件通知,社交系统等。
从中我们可以看出,并不是所有的子域都是相同对待,对于通用域我们甚至不需要良好的设计,适当的编码混乱都是可以接受的。但是无论如何,子域之间清晰的边界定义,子域的职责是必不可少的,它避免了混乱的子域实现影响了核心域。
4 模型驱动设计
领域模型驱动着代码的实现,DDD强调,无论在项目的初始阶段,还是迭代阶段,代码模型、实现与分析模型、设计密切协同。而分析模型就是对通用语言UL的描述,通用语言UL就是业务场景下的术语表。
那么,如何建立好的模型。这个问题难以被正向描述,只能被反向描述。我们说一下常见的坏模型是如何创建的。
4.1 描述用例是涉及了技术与UI
对问题的描述时,不能涉及具体的技术,和UI展示。
例如,一个用例是:当一个顾客没有收到他的商品时,他可以点击“没收货”按钮。那么他的订单会在数据库被标记丢失商品,需要重发一份免费订单。但是如果他之前已经被标记过了,那么就需要与客服沟通,而不是直接重发免费订单,客服联系快递以避免损失。
- “没收货”按钮,是UI展示
- 数据库和标记,是具体的技术实现
对用例的探讨当涉及具体的技术,和UI展示,就会不自觉地将领域模型与具体的技术复杂性耦合在一起。因此,更好的用例应该描述为:
当一个用户没收到商品时,可以请求一份索赔订单。如果该用户之前未请求过索赔订单,就会生成一份补偿订单。如果该用户之前请求过索赔订单,就会将该索赔订单分配给某个客服,由客服人工调查该订单和物流以决定是否进行补偿。
在新的用例描述中,没有具体的技术,和UI展示。而且将未明确的领域概念明确地表达出来,索赔订单和补偿订单。这两个领域概念的实现可以是数据库的一个字段标记,也可以是一个新的表,这些都是不与任何的技术复杂性绑定在一起的。而且,我们可以将索赔订单和补偿订单加入通用语言UL术语表,作为一个明确清晰的业务术语,方便业务和开发之间的沟通。
4.2 模型依赖现实关系创建
就像0.4.1和0.4.2的反例,我们是对问题域建模,而不是对现实关系建模。对现实关系建模会增加不必要的复杂性和模型切分不彻底,边界不清晰的问题。
4.3 模型描述实现所有问题
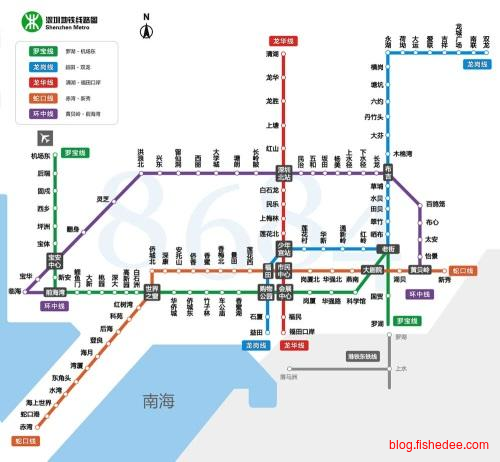
模型的存在是为了解决特定的问题,不要企图将不存在的问题都纳入模型考虑。例如,地铁上线路图,是为了乘客在地铁上了解这一站是什么,下一站是什么的问题。所以,线路图仅用点来描述一个地点,用连线来描述地点之间的关系。线路图没有企图用地貌来展示地点的样式,用曲线来描述路线的实际行走路线,地貌和曲线无助于乘客的路线困惑,它除了平添复杂性,没有带来有益的意义。
4.4 对行为抽象,而不是对概念抽象
开发者天生有灵敏的感觉,对可能抽象的地方特别敏感,这在0.4.3已经描述过这样的反例。例如,对开发者遇到,自有商城订单,第三方商户订单,合作联营订单,生鲜订单,拍卖订单,二手转卖订单,时,总会有一种冲动,企图将这些订单都抽象为一个统一订单,以减少copy/paste的代码。
但是,这是不对的。抽象的意义不是因为它们都是订单类型,概念之间有共性,所以而抽象。而是抽象的意义在于它们的行为有共性,例如,自有商城订单,和第三方商户订单,都可以共有一种优惠券,那么扣除优惠券这一部分可以成为抽象。而自有商城的下单价格,与拍卖订单的下单价格,明显是属于不同的价格体系,企图将他们抽象是不对的。所以,这些订单之间只是概念上相似,但有些订单之间的行为并不一致,不可以简单地抽象为一个统一订单。如果仅仅因为概念相似而抽象,就会让抽象代码里面写很多if/else来处理各自订单体系的特殊逻辑,让维护变得困难。
使用抽象统一的技术,不妨采取延迟的策略,先为每个具象写不同的代码,即使它们暂时有重复的地方也无妨。然后在需要重构的时候,再各自查看它们之间的行为共性,这些共性是否是稳定的,只有在共性稳定的情况下,才去使用抽象来抽取相同代码。
5 领域模型实现模式
我们有了模型以后,有多种方式可以实现它。具体要用哪些方式,要看模型是否核心,它的业务复杂度如何。
5.1 事务脚本
func transfer(fromAccountId int,toAccountId int,amount int){
this.DB.Update("update t_account set amount = amount - ? where accountId = ? ",amount,fromAccountId);
this.DB.Update("update t_account set amount = amount + ? where accountId = ? ",amount,toAccountId);
}事务脚本的方式就是在,全部用过程式编程,sql操作和业务逻辑全部混在一起写,很显然,这种方式业务复杂度高的时候就会开始混乱
5.2 表模型(贫血模型)
type AccountRow struct{
AccountId int
Amount int
}
type IAccountDb interface{
func Get(accountId int)AccountRow
func Mod(accountId int,account AccountRow)
}
func transfer(fromAccountId int,toAccountId int,amount int){
db := NewAccountDb()
fromAccountRow := db.Get(fromAccountId)
if fromAccount.Amount - amount < 0{
Throw(1,"账户透支了")
}
toAccountRow := db.Get(toAccountId)
fromAccountRow.Amount = fromAccountRow.Amount - amount
toAccountRow.Amount = toAccountRow.Amount + amount
db.Mod(fromAccountId,fromAccountRow)
db.Mod(toAccountId,fromAccountRow)
}表模型,就是类,例如IAccountDb代表一个数据表,它封装了对这个表的修改和查询操作,查询的时候返回的是行信息。至于对象AccountRow,仅仅是作为一个行的数据容器,没有行为,只有数据。所以称为AccountRow的方式为贫血模型。
AccountRow暴露了所有的字段,任由外部去修改它,违反了接口”只说不问”的原则。该原则是说,对象的工作内容和职责,是通过它自身用方法来暴露自身职责来表达,而不是通过暴露所有字段来表达职责,这限制了使用方可以做什么,而不可以做什么。暴露所有字段的方式太过灵活,却让职责推卸给了使用方。
5.3 活动记录模型(充血模型)
type AccountRecord struct{
accountId int
name string
amount int
}
func (this *AccountRecord) Deposit(amount Amount){
this.amount = this.amount + amount
}
func (this *AccountRecord) Redraw(amount Amount){
if this.amount - amount < 0{
Throw(1,"账户透支了")
}
this.amount = this.amount - amount
}
func (this *AccountRecord) Save(){
GlobalDB.Update("update t_account set amount = ? and name = ? where accountId = ? ",this.amount,this.name,this.accountId);
}
func GetAccount(accountId int) AccountRecord{
rows := GlobalDB.Select("select * from t_account where accountId = ? ",accountId);
if len(rows) == 0{
Throw(1,"找不到该账号")
}
return AccountRecord{
accountId:rows[0],
name:rows[1],
amount:rows[2]
}
}
func transfer(fromAccountId int,toAccountId int,amount int){
db := NewAccountDb()
fromAccountRecord := GetAccount(fromAccountId)
toAccountRecord := GetAccount(toAccountId)
fromAccountRecord.Redraw(amount)
toAccountRecord.Deposit(amount)
fromAccountRecord.Save()
toAccountRecord.Save()
}活动记录模型,就是类,例如AccountRecord代表一个数据表的行,而不是整个表,它封装了对这个行的修改方法以及数据。另外,它取代了表模型的IAccountDb,它自身就能执行数据库的查询和持久化操作。由于对象AccountRecord,同时具有行为和数据。所以称为AccountRecord的方式为充血模型。
显然,对象AccountRecord的使用更具有可读性,它的字段都是私有的,只能通过方法来修改它,不能直接修改它的字段,保证了它的安全性和表达了它的职责。但是,这种方法依然是面向数据表而编程,对表的结构发生变化时,代码仍然需要改变。例如,当Account改为用两个表来存放数据,一个表存名字,另外一个表存余额的时候,这种方式就要重写代码。
5.4 领域模型
领域模型,是介乎于充血模型和贫血模型的实现方式。它的目标是让技术复杂性和业务复杂性隔离开。它的领域层代码是假设没有数据库的通用业务代码,仔细看一下它和活动记录模型的区别。
//领域层,封装的是业务复杂性
type Account struct{
accountId int
name string
amount int
}
func (this *Account) Deposit(amount Amount){
this.amount = this.amount + amount
}
func (this *Account) Redraw(amount Amount){
if this.amount - amount < 0{
Throw(1,"账户透支了")
}
this.amount = this.amount - amount
}
func (this *Account) SetName(name string){
this.name = name
}以上是领域层代码,封装的是业务复杂性
//基础设施层,封装的是技术复杂性
type AccountRepo struct{
}
func (this *AccountRepo) GetById( accountId int) Account{
rows := GlobalDB.Select("select * from t_account_amount where accountId = ? ",accountId);
rows2 := GlobalDB.Select("select * from t_account_name where accountId = ? ",accountId);
if len(rows) == 0 || len(rows2) == 0{
Throw(1,"找不到该账号")
}
return Account{
accountId:accountId,
name:rows[1],
account:rows2[1],
}
}
func (this *AccountRepo) Save(account Account){
GlobalDB.Update("update t_account_amount set amount = ? where accountId = ? ",account.amount,account.accountId);
GlobalDB.Update("update t_account_name set name = ? where accountId = ? ",account.name,account.accountId);
}以上是基础设施代码,封装的是技术复杂性
//应用层,负责编排领域层,基础设施层
func AccountAppliaction struct{
}
func (this *AccountAppliaction) Transfer(fromAccountId int,toAccountId int,amount int){
//取出实体对象,加载到内存上
fromAccount := AccountRepo.GetById(fromAccountId)
toAccount := AccountRepo.GetById(toAccountId)
//在内存上执行业务逻辑
fromAccount.Redraw(amount)
toAccount.Deposit(amount)
//将内存上的实体对象,保存到存储库
AccountRepo.Save(fromAccount)
AccountRepo.Save(toAccount)
}应用层,负责编排代码,应用层总是使用0.6节的三步流程来实现代码。注意,领域层的Account是既没有对应数据库的一个表,也没有对应数据表的一个行,它就是业务对应的一个概念或术语。这个Account可以任意嵌套多层对象,例如,Account可以包含多个地址的通讯地址列表,也可以用不被数据库支持的任意数据类型,例如数组类型,数字和单位组合的货币类型等等。至于,这么复杂结构的Account是如何读取,或者保存到数据库上的,那是AccountRepo的责任,跟Account无关。因此Account可以完全放飞自我,在不考虑任何技术复杂度的情况下,尽可能拟合模型的要求。
可以看出,领域模型的实现方式,既有行为也有数据,但是绝不包含任何技术复杂度的代码。
5.5 函数编程模型(不可变模型)
//函数编程下的任意数据结构的字段都是一旦赋值就不能修改的,只能读不能写
type Account struct{
accountId int
name string
amount int
}
func AccountRedraw(account Account,amount int) Account{
if account.amount - amount < 0 {
Throw(1,"账户透支了")
}
return Account{
accountId:account.accountId,
name:account.name,
amount:account.amount - amount,
}
}
func AccountDeposit(account Account,amount int) Account{
return Account{
accountId:account.accountId,
name:account.name,
amount:account.amount + amount,
}
}
func Transfer(fromAccountId int,toAccountId int,amount int){
//取出实体对象,加载到内存上
fromAccount := AccountRepoGetById(fromAccountId)
toAccount := AccountRepoGetById(toAccountId)
//在内存上执行业务逻辑
fromAccount = AccountRedraw(fromAccount,amount)
toAccount = AccountDeposit(toAccount,amount)
//将内存上的实体对象,保存到存储库
AccountRepoSave(fromAccount)
AccountRepoSave(toAccount)
}函数编程模型下,它的特点是数据是不可变的,所以它采用的贫血模型,数据不能直接改变,只能返回新的数据。这种方法需要函数编程下的不可变数据结构的支持,就不多说了。严格来说,这是一种领域模型的实现,但是很小众。
6 使用有界上下文维护领域模型的完整性
6.1 有界上下文的意义
对于每个子域,我们都有一个解决域对应它,这个域我们称为有界上下文
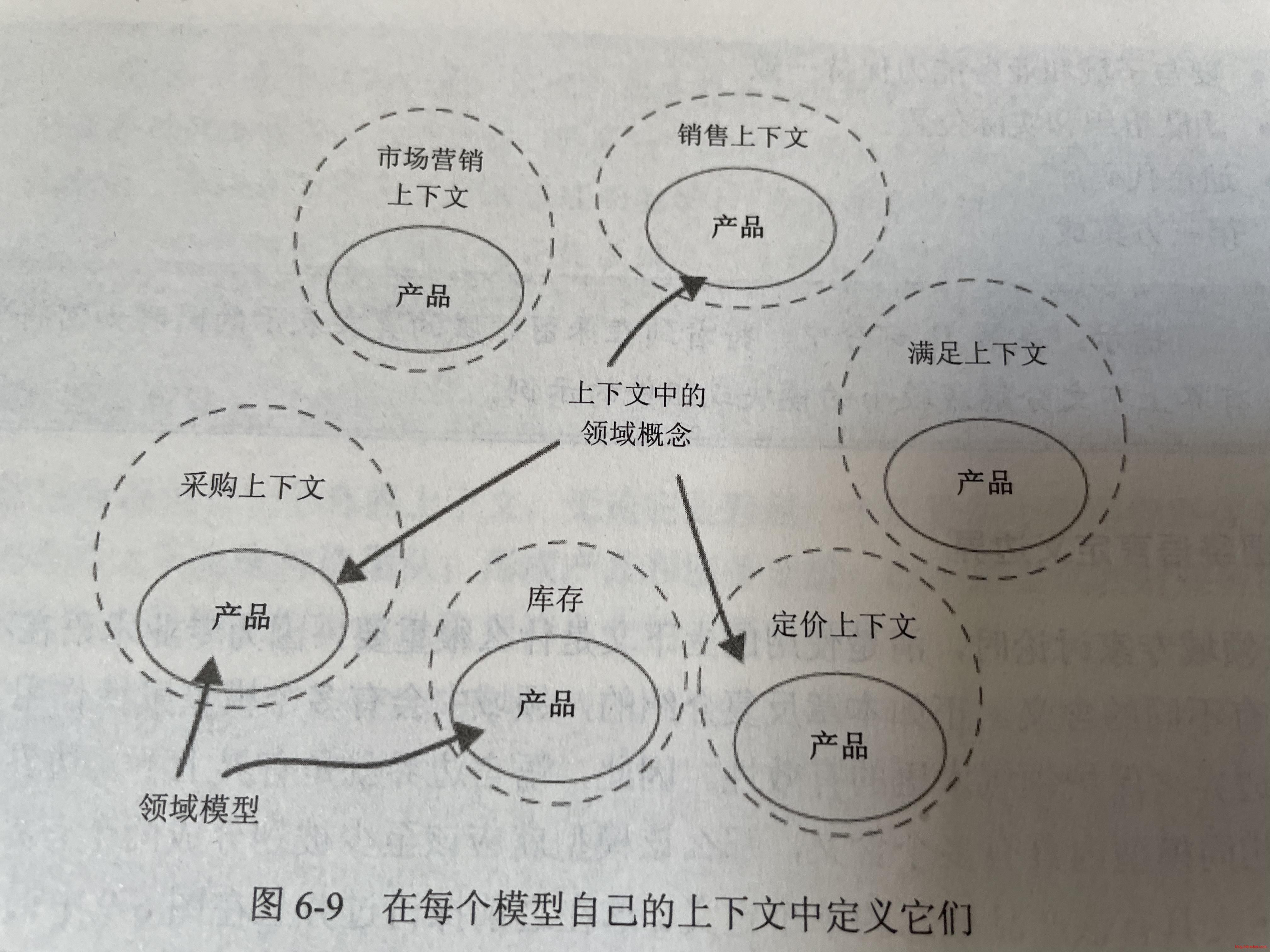
有界上下文是业务的边界,具体指:
- 通用语言UL的边界,例如产品在库存和采购上下文都是有的,它们的业务意义是不同的。但是即使在不同上下文都可以用同一个名字“产品”来代表各自业务的术语而不会产生混淆。因为就像每个国家都有不同的手语意义,当跨国国界以后,同一个点头样子是一样的,但它们的意义是不同的。而且,点头在特定的国家里面是没有歧义的。因此,我们可以在单个有界上下文肆意使用不同名字来表达通用语言,而不用担心和其他有界上下文冲突。
- 模型的边界,一个有界上下文就对应一个模型。你不需要也不应该去对整个系统创建一个模型。
- 团队的边界,一个有界上下文就对应一个团队来维护,你不应该让多个团队维护一个有界上下文,这会让协作效率大幅下降。
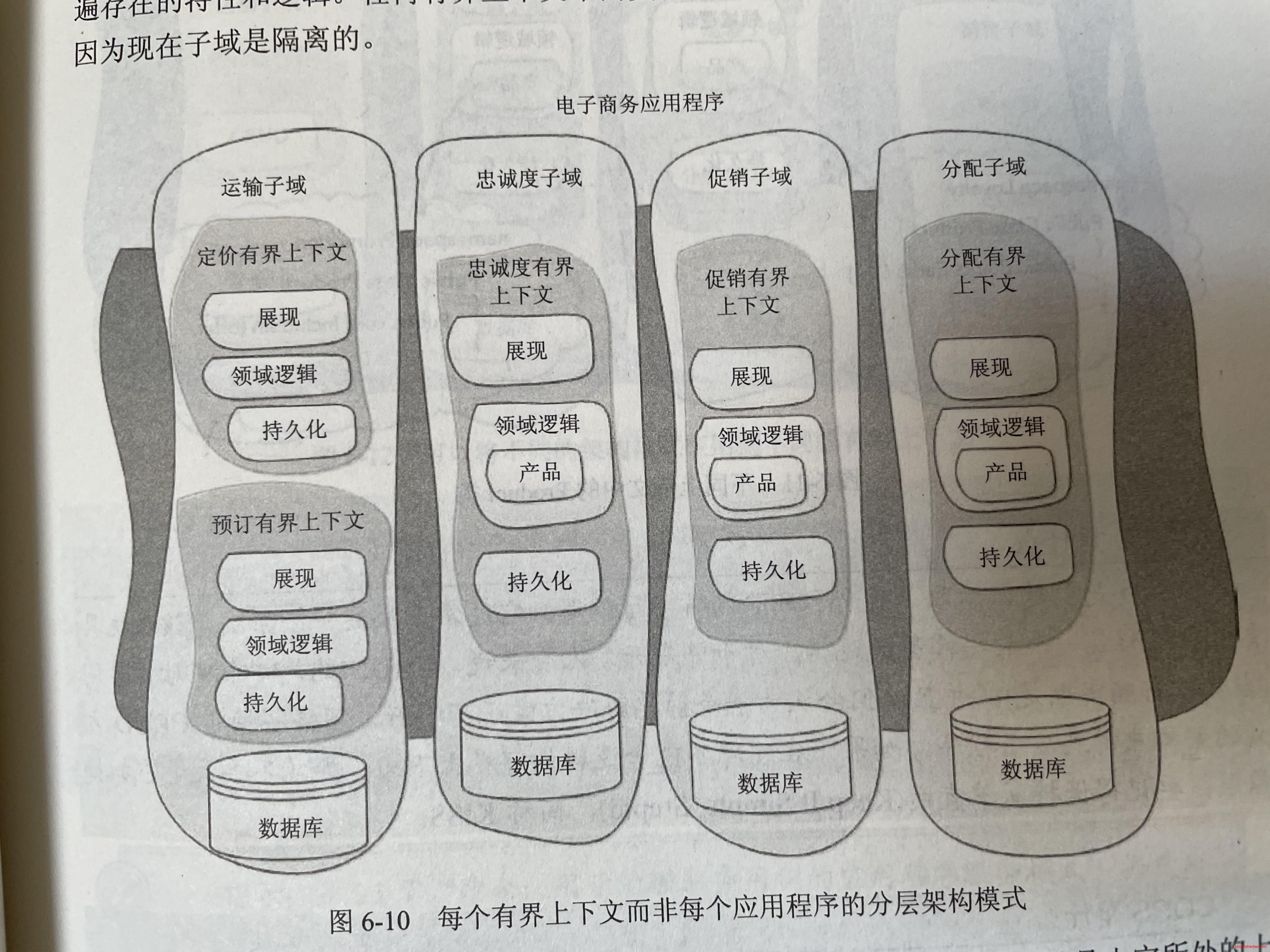
有界上下文更是代码,数据和部署的边界,不同的有界上下文有自己的代码仓库,数据库和机器,不同有界上下文需要交流的话需要明显的方式,例如,事件通知,RPC通信,不允许直接共用代码或者共用数据库的方式来交流。因为一旦违反的话,就会让其他上下文的模型容易侵入到自己的上下文中,造成模型混乱。而且,麻烦的交流方式也会让划分问题域的时候尽量思考清楚,更好的划分会产生更少的跨上下文交流。
6.2 有界上下文的局限
有界上下文,实际是对写入数据职责的划分。对于读取数据时,我们在某些场景下需要多个有界上下文的协同展示。
6.2.1 复合UI
当一个UI需要多个有界上下文的数据时,有几种方式:
- 后端数据的在线join操作,在后端的应用层,直接调用数据库将多个上下文的表join在一起,返回。这就是在线join的方法,简单粗暴,就是效率不太高而已。
- 后端数据的离线join操作,使用elasticsearch,flink等技术流式处理,join多个表,生成一个物化视图,查询的时候直接将视图查询后返回就可以了,这就是离线join方法。
- 前端数据的join操作,用ajax将来自多个不同上下文的数据join在一起显示。这样做的好处在于,当后端任意一个有界上下文崩掉后,前端都可以进行相应的降级操作,避免了单点故障。但是,在前端层的性能很低,而且不支持多有界上下文数据的组合筛选操作。
- 前端UI分块,单个页面分为多个UI块,各个块由各自的有界上下文来控制输入和展示,在这里能看到一个精彩的例子
6.2.2 报表
做报表的时候,需要多个有界上下文的数据协同分析得出结果,这需要使用数据仓库的技术。用ETL抽取多个数据库的数据到统一的地方,例如HDFS,或者Greenplum,然后使用Hive等方式生成报表。值得一说的是,数据量少的时候,直接用一个postgresql聚合多个数据库的内容,再做OLAP分析就可以了,简单效率过得去,pg有很方便的fds工具轻松抽取多个数据库的内容,而且OLAP的优化器足够好,支持的语法特别多,跑起来比mysql又快又方便。
7 上下文映射
7.1 上下文映射的意义
上下文映射就是用图的方式描述不同上下文之间的关系,显示了模型是如何彼此相关以及团队是如何彼此相关的。它的意义是:
- 揭示有界上下文之间数据的集成点和流向,有助于技术上的集成
- 展示了有界上下文的团队关系,有助于协作
7.2 有界上下文的关系
有界上下文的关系有:
- 共享内核,将自己的上下文和对方的上下文直接共享部分的数据表。这是一种非常紧密,而且较高风险的集成,仅用于两个团队有非常多的重叠领域模型。
- 合作关系,两个团队的关系比较紧密,两者的API都是为对方的需求而设计,这也是一种比较紧密的集成方式。适用于两个团队的业务紧密,而且只有双方的情况。这是一种双向的集成。
- 上下游关系,上游团队独立开发,下游团队只能提需求,甚至只能遵循上游团队的模型。这是一种最为常见的,而且宽松的集成模型。
- 开放宿主服务OHS,开发宿主服务提供公共API,展示它的简化模型,以帮助多个其他的上下文集成自己上下文的数据。
- 防腐层ACL,将自己的上下文里面,创建一个防腐层,以避免其他上下文的模型渗透到自己的上下文里面。防腐层的工作就是转译逻辑,而不包括业务逻辑。
- 分道扬镳,对于小众且不重要的数据集成需求,让用户手工复制粘贴数据来集成,而不是让两个上下文直接自动集成。两个上下文之间没有数据集成和沟通的渠道,各自往自己的方向演化,这是最为宽松的集成。
8 应用程序架构
8.1 领域层
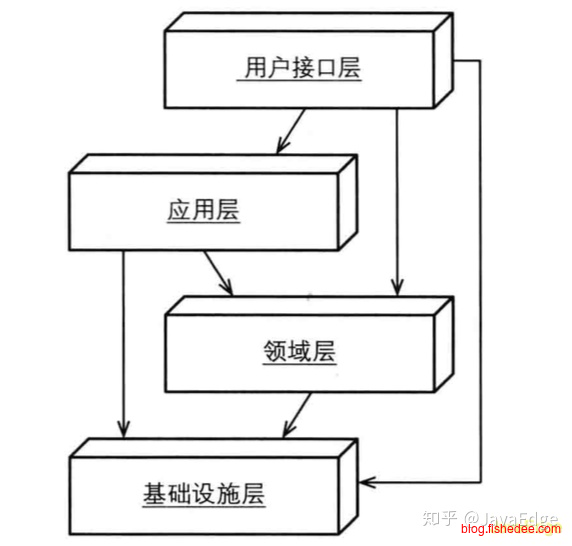
type Forum struct{
FormId int
}
func (this *Forum) CreatePost(title string) Post{
post := Post{
PostId:UUID(),
FormId:this.FormId,
Title:title,
}
this.queue.Publish("post_created",post)
return post
}领域层就是纯碎的业务逻辑的地方,不涉及展现和持久化。早期的DDD应用架构中,DDD依赖于基础设施层,例如,依赖消息队列接口以发布事件。但是这样做会让领域层与技术复杂性耦合在一起,让基础设施变化的时候,领域层也要跟着改变。
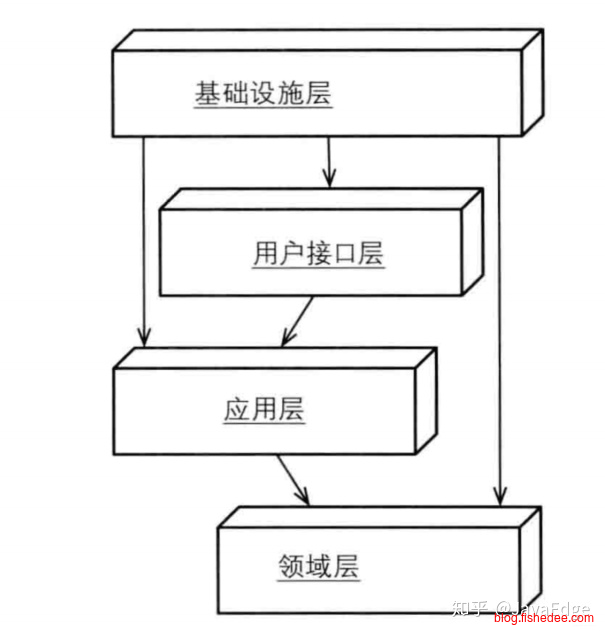
//领域层
type FormEvent interface{
Publish(post Post)
}
type Forum struct{
FormId int
}
func (this *Forum) CreatePost(title string) Post{
post := Post{
PostId:UUID(),
FormId:this.FormId,
Title:title,
}
this.formEvent.Publish(post)
return post
}
//基础设施层
type FormEventImpl struct{
}
func (this *FormEventImpl) Publish(post Post){
this.queue.Publish("post_created",post)
}通过使用依赖倒置的模式,让领域层依赖一个接口,然后基础设施层实现这个接口,从而解耦了它们之间的依赖。同时,接口的方式让单元测试也变得简单。
关于依赖倒置,vs code有一个漂亮例子。但是,也要注意,依赖倒置并不是简单地只依赖接口,而不是依赖实现就能达到解耦的效果,关键在于两者的业务逻辑是否真的可以倒置。在这里有一个类似的例子,它的正确解决办法不是应该用依赖倒置,而是将底层切分成多个可抽象小粒度,然后根据不同的场景建立自己专属的编排代码,再也不去复用一个公共的购物车和收银台。
最终,在这个设计下,领域层提供了接口约束基础设施服务层。
8.2 基础架构层
封装了消息队列,数据库,和缓存等的技术复杂性,他们都是根据领域层提供的接口来对应实现的。
8.3 应用服务层
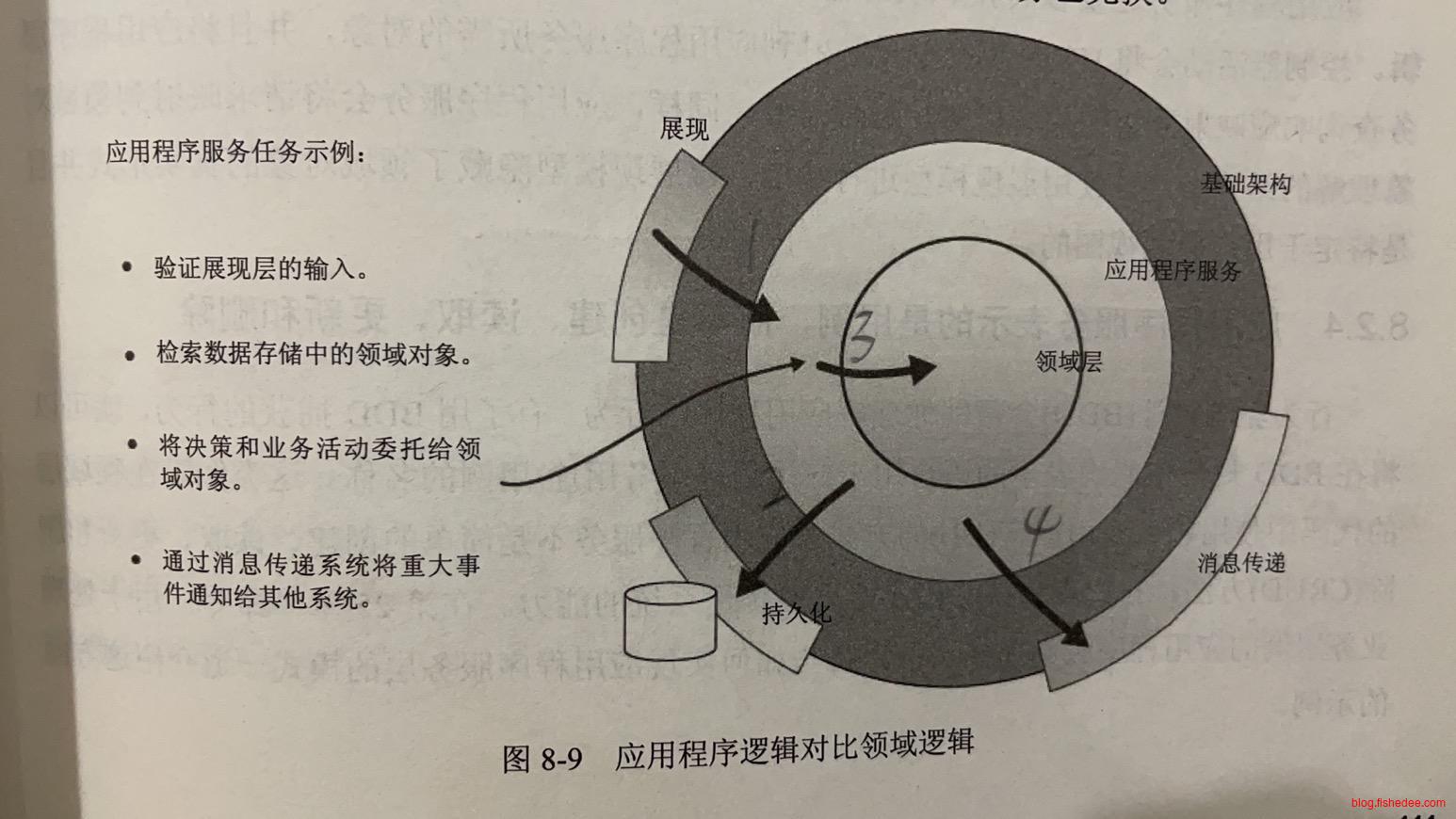
应用服务层的职责:
- 编排领域服务,和基础设施层。值得注意的是,应用服务层不会直接依赖基础设施层,它使用的是领域层依赖的解除设施接口来编排的。所以,从图中可以看到,基础设施层在外层,应用服务层在中层,领域层在最下面。
- 为用例服务,提供用例的接口约束
- 负责用例的输入数据和输出数据的DTO,与领域对象DomainObject的相互转换。从这个角度看,应用服务层,是领域层的防腐层,避免用例的DTO影响领域层的变化。
8.4 接口层
接口层,就是处理不同的客户端的输入和输出。这一层非常薄,就是将不同客户端的输入和输出,转换为应用服务层的DTO。每个接口对应应用服务层的一个用例。因此,对应像Web客户端,安卓客户端,ios客户端,它们可以共用一个应用服务层,而有三个不同的接口层。
一般来说,对应只有一个客户端的情况,例如是ajax客户端,完全可以与应用服务层合成一层。这个也是之前说的例子
8.5 上下文与应用服务层的集成
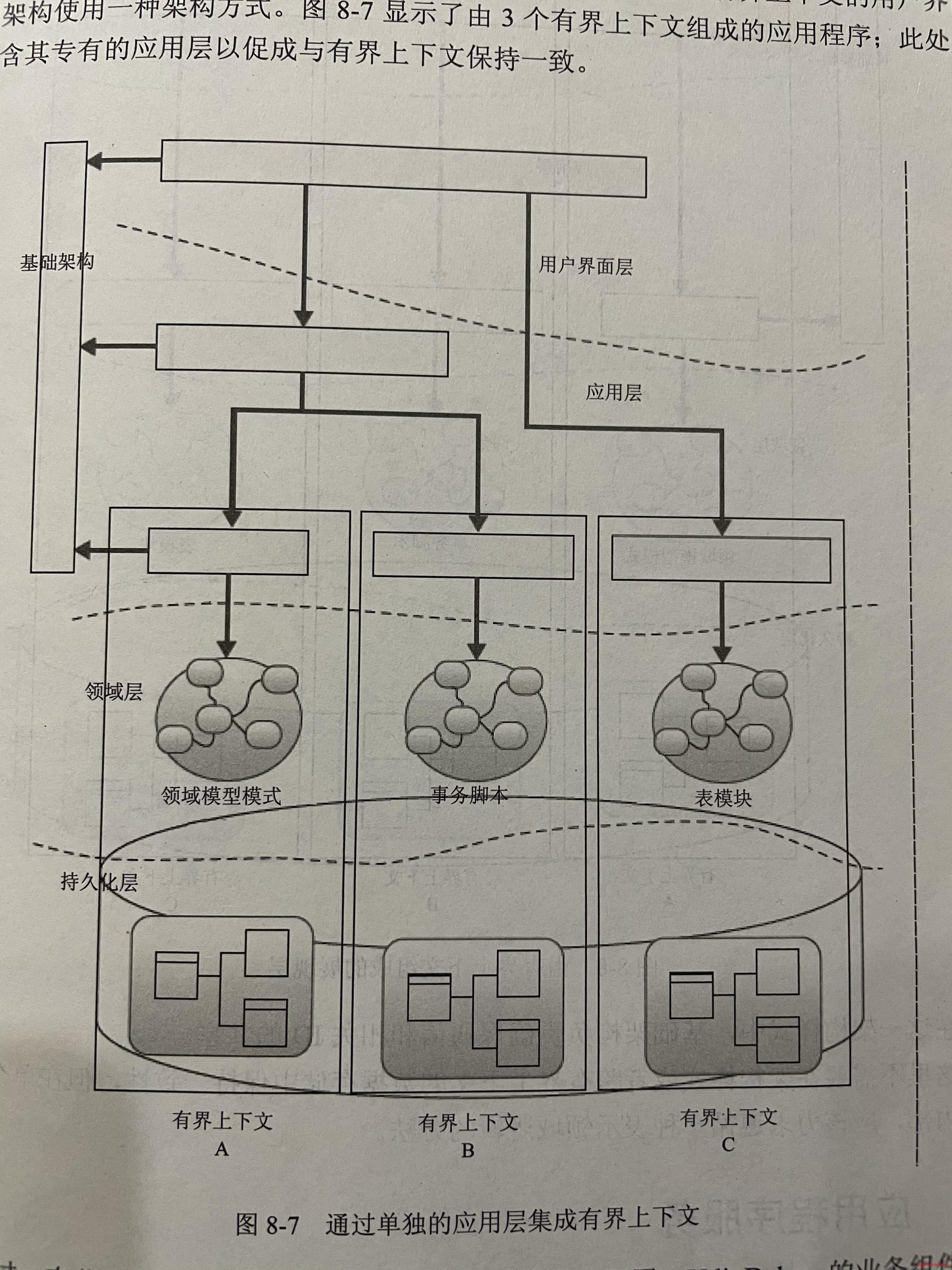
不同的有界上下文应该使用不同的代码仓库,不同的数据库和部署环境中。一种简化的要求是,不同的有界上下文必须隔离使用不同的数据库,但是代码仓库和部署环境可以保持一致。那么,这样不同的有界上下文就会共享同一个应用层。
这时候的应用层会根据不同的有界上下文来编排业务逻辑和基础设施层,并负责不同有界上下文通信时,不同有界上下文的领域对象的转译。
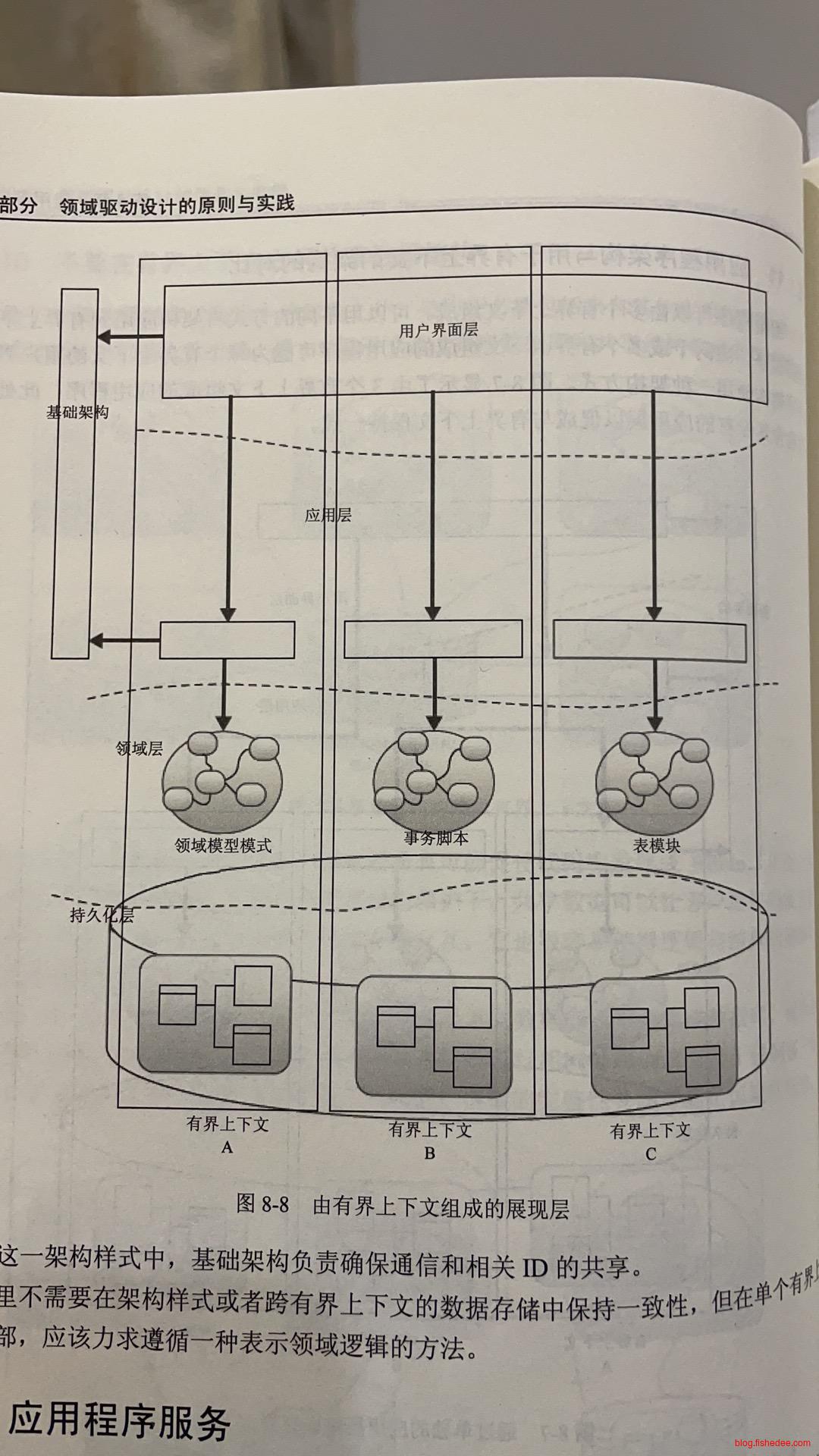
另外一种方法是,在UI层聚合多个不同上下文的数据。一个页面的不同UI由各自的上下文来自主显示。
8.6 测试
我们来看看这样的应用程序架构会给测试带来什么?
- 领域层,领域对象都是无关持久化,所依赖的基础设施层都被接口所替代的。所以可以做几乎无mock的单元测试,可靠,安全,快速。
- 应用服务层,应用服务层负责编排基础设施层与领域层,它实际上依赖的是领域层所定义的基础设施层接口,这个层无关表,无关行,接口都是简单的Get和Save接口,用mock很容易做。所以,应用服务层可以很容易做,端到端的测试。持久化设施的mock可以简单地用内存实现来代替。
- 基础设施层,接口简单,需要连接到真实的数据库来做测试,速度慢,可靠性低。但这部分代码一般都比较简单,不需要专门的测试。
DDD的架构真正地摆脱了持久化依赖所带来的测试困难的问题。
9 团队开始应用领域驱动设计通常会遇到的问题
无论是哪个工作岗位,它的职责都是为公司创造价值。而且,创造价值都是在一定的资源限制下。开发也是不例外,使用DDD也无法违反这个原则。所以,我们总是希望,DDD能用最小的资源创造最大的业务价值。同样地,我们可以看看使用DDD时的一些反模式。
9.1 过分强调战术模式
DDD的核心在于创造业务价值,更好的协作,和子域划分能比战术模式提供大得多的价值。所以,不要本末倒置,将强调使用实体,值对象,聚合根,事件,领域对象的这些战术模式看成是DDD的核心。进一步来说,即使没有这些战术模型,仅仅使用子域划分,上下文,公共语言协作就可以看成有效的DDD模式。
同理,DDD的关键也不在于是否使用了CQRS,事件溯源,RESTful服务,消息队列,ORM这些技术性的架构
9.2 忽略语言,协作和上下文
DDD的核心在于语言,协作和上下文,它为什么能创造更大的业务价值
- 上下文能让模型纯净和专注,更容易维护和测试。
- 公共语言是业务和开发沟通的桥梁,能让两者可以双向协作。从根本上避免,开发输出的代码与业务想要的相差太远。
- 协作是强调两者互相沟通,在开发前就能提前找到业务模型的不足
9.3 在非核心域花费太多时间
只有核心域才值得使用DDD的战术模型,通用语言的UL建模,支撑域与通用域完全可以使用通用模块,或者简单地用CRUD的模式来实现。但是,无论用哪种模式,对子域和上下文的划分都是必不可少的。因为上下文保证了每个域之间的模型不会互相渗透和影响,保持了模型的纯净和专注。
9.4 低估DDD的成本
DDD的通用语言UL建模,战术模式是非常耗费时间和人力资源的,对于快速上线有要求的业务,或者早期前景不明朗的业务,使用DDD是一个巨大的资源浪费。DDD更适合用于需要长期迭代和维护,高业务和技术复杂度的业务。
- 时间资源大,UL和协作都需要花费更多的前期时间
- 人力资源大,学习曲线陡峭,需要业务专家介入生成模型
10 应用DDD的原则、实践和模式
10.1 DDD的实施步骤
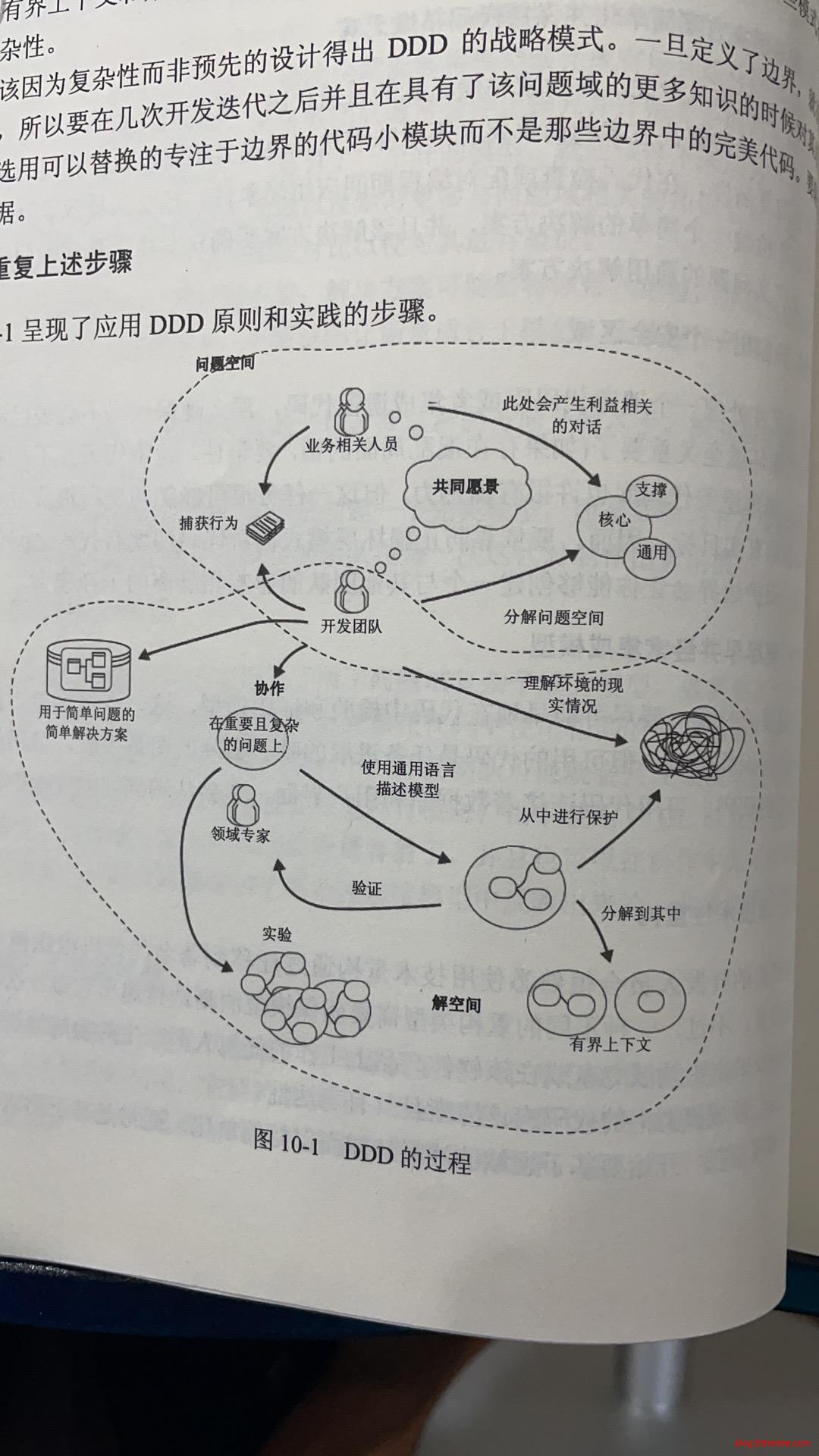
一图胜千言
10.2 DDD建模提示
DDD建模的一个技巧是,让隐式内容显式化。
- if/else代码可能代表着一个隐式Policy,命名这个Policy让领域概念暴露出来。
- 让人困惑的用例可能蕴含一个未命名的领域概念,尝试命名它,然后重写用例。
11 有界上下文集成介绍
11.1 有界上下文的自主性
衡量团队协作效率的方法,可以用WIP(Working In Progress),就是看各个团队中有多少个工作是在等待与其他团队合并和联调当中。如果WIP很多,这证明团队之间的边界不明显,各个团队的业务不能被独立演化,需要与其他团队不断联合才能前进。这个问题的根本原因在于,上下文划分不彻底,边界不清晰导致的。上下文是:
- 业务逻辑的边界
- 物理代码和部署的边界
- 团队协作的边界
11.2 遗留系统集成的方法
对于已经存在的遗留系统,我们有多种方法来集成它。
- 气泡上下文,建立一个逻辑独立的上下文,当需要数据的时候向遗留系统同步调用,同时使用ACL保护自己的上下文不被遗留系统的模型影响。
- 自主上下文,与气泡上下文唯一不同的是,使用消息来异步同步遗留系统数据,这使得数据也是独立自主的了。
- 公开服务,为遗留系统建立一个公开服务,来方便多个外部上下文的调用,这方便了多个上下文建立厚的相似的ACL来保护各自的上下文
11.3 集成方法
上下文的不同集成方法
- 数据库,上下文之间使用数据库作为消息队列,轮询来实现数据通知。简单,但是有单点故障,而且无扩展性,有锁。
- 平面文件,无锁,但没有固定格式,开发过于灵活。
- RPC,简单,上市快,但是同步调用响应慢,可能产生级联故障。
- 消息队列,体验最好,异步响应快,自带故障重置,但是开发复杂。
11.4 有界上下文与SOA
SOA与微服务只是相同思路的不同技术实现而已,它们的想法都是将代码成多个小模型,各自开发与部署。SOA与上下文的关系是,上下文的划分粒度更大,SOA的划分粒度更小。SOA划分应该为上下文的子业务组件,例如是运输上下文的,优先运输业务组件与标准运输业务组件。
SOA与上下文的共同点在于,SOA之间应该保持数据库,代码,部署环境的隔离,尽量避免同步的依赖关系。同一个上下文的多个SOA可以交由同一个团队来维护与开发。
12 通过消息传递集成
12.1 可靠性
消息传递要实现可靠性需要满足
12.1.1 存储转发模式
发送方消息发送给消息中间件,然后由消息中间件发送给接收方。这样能让发送方和接收方任一个不在线的时候,消息依然能可靠地发送和接收。
12.1.2 发送方可靠性
发送方的业务逻辑在数据库上运行,消息中间件在另外一台机器上运行,两者属于分布式的,我们需要一种方式保证业务逻辑执行完毕以后,发送消息不会丢失,有几种方法。
- XA事务,使用支持XA事务的数据库与队列来实现发送可靠性,但这种实现性能很低,而且支持XA事务的数据库与队列不多。
- 半消息,让消息系统提供反查机制来保证原子性,例如RocketMQ的事务消息
- 定时器,将发送消息写入数据库,然后由定时器定时扫描数据库,发送成功完以后设置数据库,该消息已经被发送。注意,这样做可能会产生发送方的消息重复,因为可能定时器可能在发送成功后宕机,也可能消息队列的发送成功的RPC丢失了。所以,这个方法,需要消息队列提供去重机制。
- CDC,跟定时器的方法类似,只是换成了,由cancal等工具监测数据库的变动(称为CDC),然后发送消息到消息队列。这个方法相对定时器的好处在于,CDC的延迟性更低。
12.1.3 接收方可靠性
一般消息队列都会提供至少一次的保证,当接收方接收消息,并处理业务逻辑成功后,返回ACK给消息中间件。如果消息中间件没有收到ACK,就会不断重试发送消息给接收方。
所以,为了接收方的可靠性,接收方可能会收到重复的消息,在业务逻辑层面需要提供幂等性的支持。
12.2 消息与网络RPC
网络RPC是最常见的会产生错误的地方。使用消息传递可以避免这种情况,消息传递会在当业务逻辑失败的时候,重试发送,直至成功为止。
以这种方式利用消息传递的场景有,发送邮件和推送,支付网关等。
12.3 消息桥
对于同一个上下文的消息传递,可以简单地通过多种方式来实现消息传递。但是对于跨上下文的消息传递,我们要考虑消息队列的跨平台特性,以及领域对象跨上下文传递的时候会产生逻辑泄漏的问题。
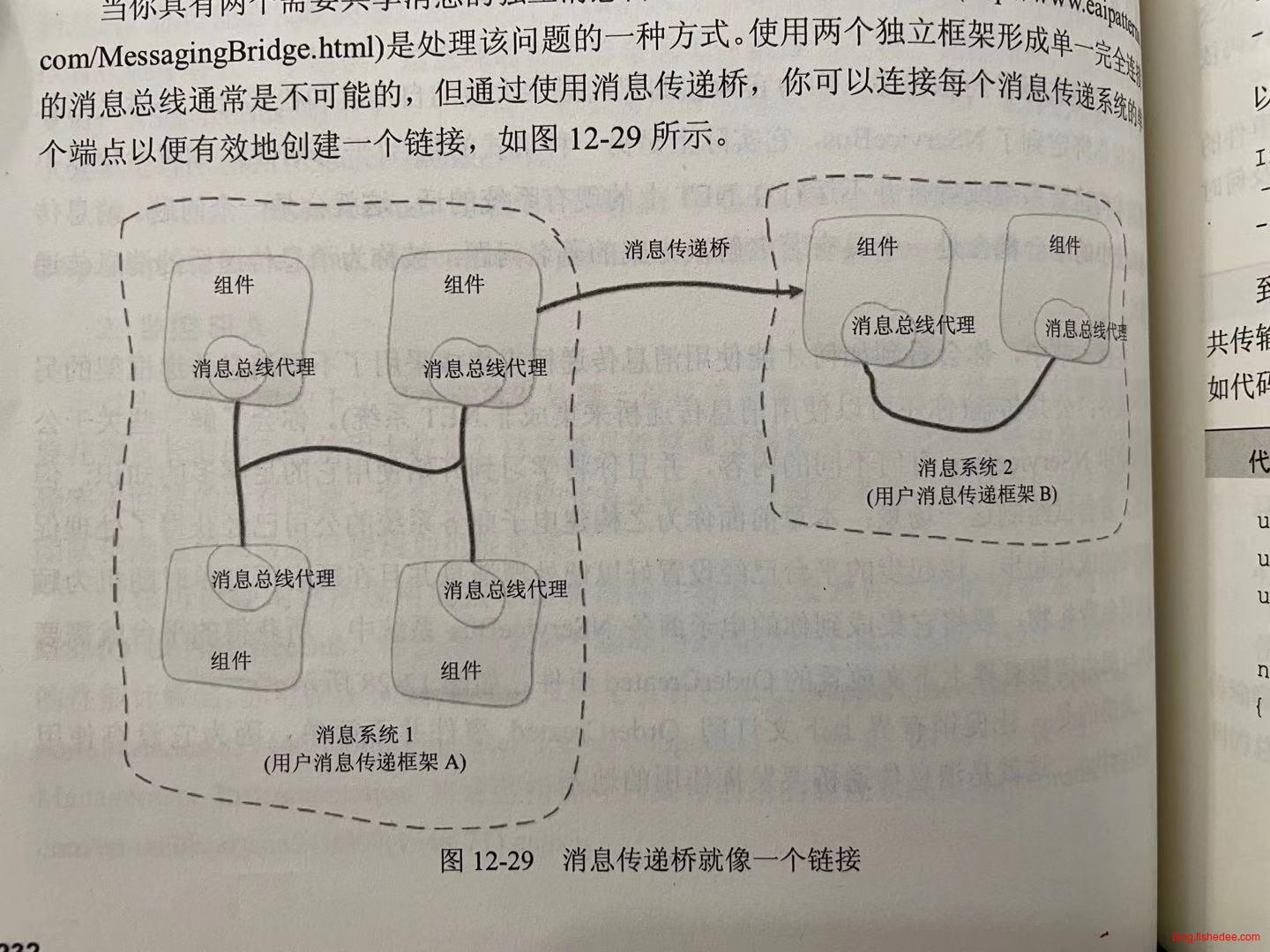
所以,对于跨上下文的消息传递,我们采用消息桥的方式来实现。倾听本地的消息队列,然后将领域事件转换为公共的领域事件,再发送到公共的消息队列上。
13 通过使用RPC和REST的HTTP来集成
这个平时实践很多了,就不啰嗦了。值得注意的是,可以用RPC来实现消息传递,就是提供接口该外部上下文来轮询,但是这种方式性能不佳,而且也不可靠。
14 构造块领域建模介绍
其实,前13章是DDD最核心的思想,第14章以后仅仅是DDD的一种领域实现模型而已,它提供了一种高度可测试性的领域模型实现。
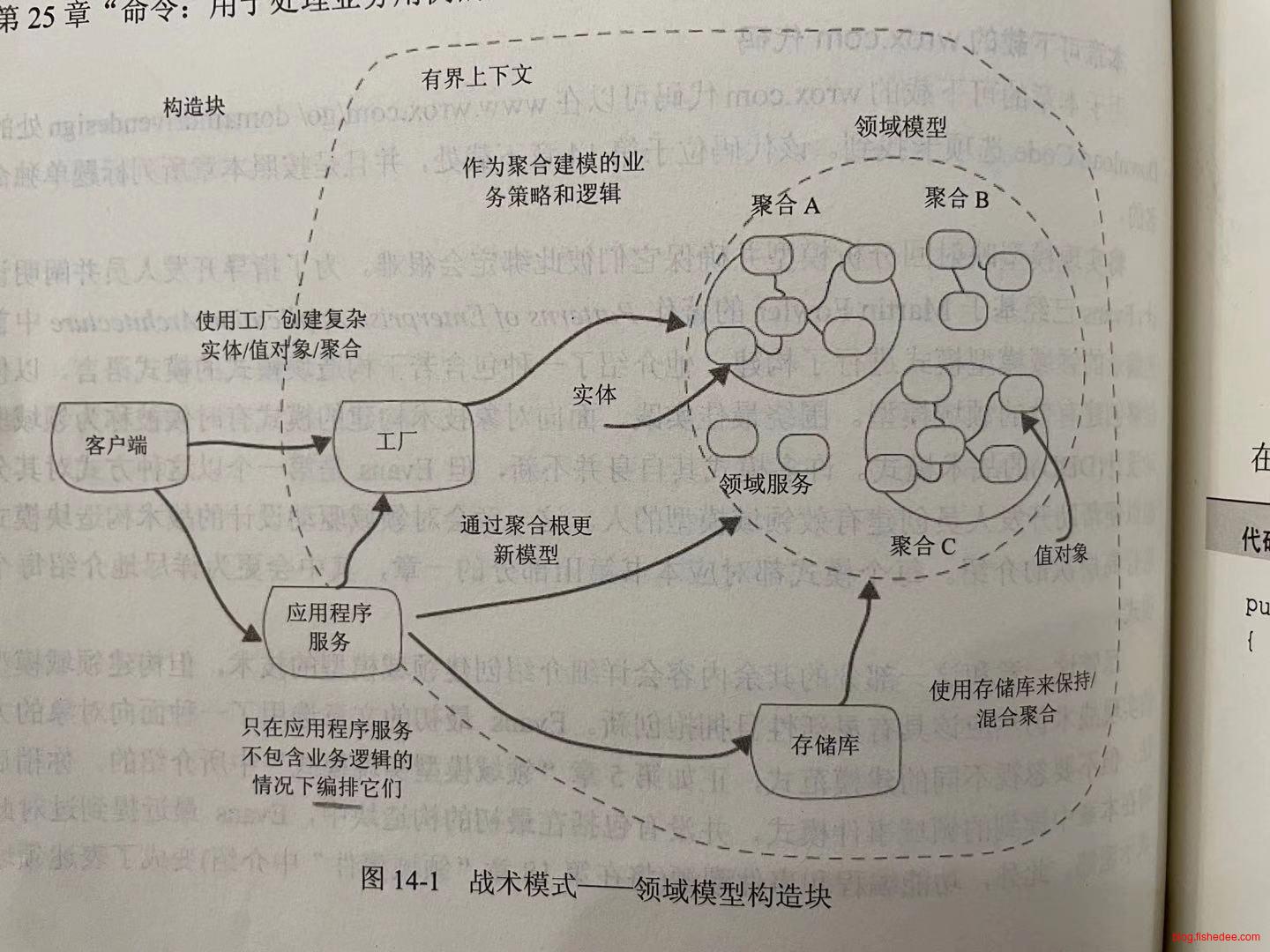
简要说说战术模型的每个工具的意义。
- 实体,表达领域概念,由身份来定义,可修改性,总是具有身份id。例如,订单,产品,用户。
- 值对象,表达领域概念,由特性来定义,不可修改性,不具有身份id。例如,运输地址,订单内的商品列表,快递信息等。
- 聚合,它是实体与值对象的聚合,它保证了领域修改的原子性。这可是最为困惑的地方。
- 领域服务,无状态的领域对象,职责为使用实体和值对象编排业务逻辑,例如运输成本计算器,转账汇率和手续费计算器,禁止使用优惠券的规则等等。
- 存储库,职责为保存或者读取一个聚合对象
- 工厂,隐藏领域对象创建的复杂性
- 领域事件,记录模型的变更,或者跨聚合(或者跨上下文)的一种通信方式。
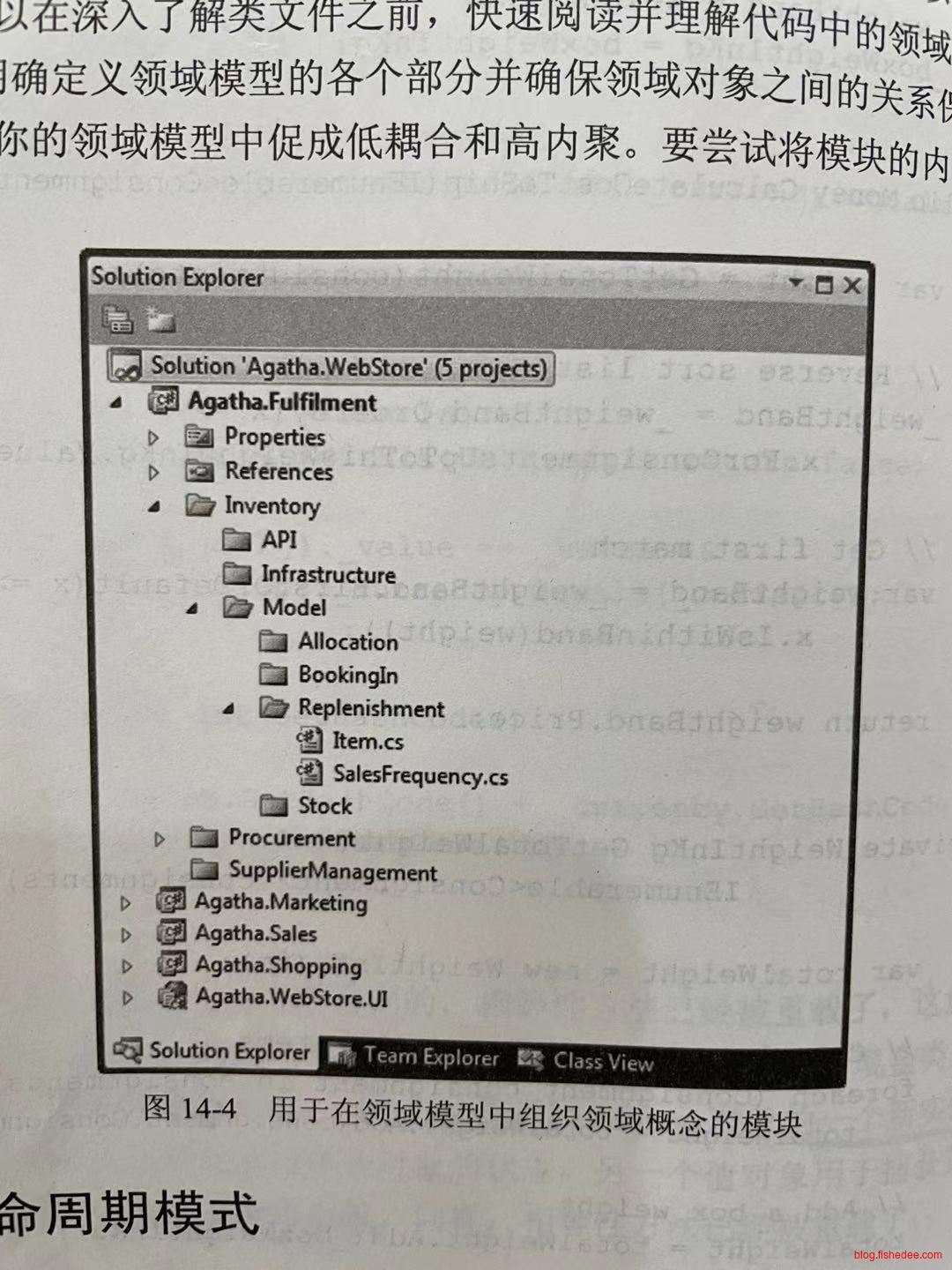
这是DDD中推荐的一种目录结构。顶级目录是所在的上下文名称,API目录是应用服务层和接口层,Infrastructure目录是基础设施层,保存存储库的实现和事件发送器。Model根据上下文的不同领域对象分目录,每个目录都是放实体,值对象,聚合,领域服务,领域事件,工厂等业务复杂性,以及存储库的接口,消息队列的接口。
15 值对象
15.1 欠缺身份
值对象是欠缺身份,仅表示描述性的领域概念。例如,货币,长度,高度,订单项。值对象由于欠缺身份,它是没有像实体一样的id值。值对象仅通过它们的属性来区分它们。
15.2 不可变,只读属性
type Money struct{
amount int//数量
currency int//单位
}
func NewMoney(amount int,currency int) Money{
if amount < 0{
Throw(1,"数量不能为负数")
}
return Money{
amount:amount,
currency:currency,
}
}
func (this *Money) GetAmount() amount{
return amount
}值对象一旦创建创建后就不能改变,方法只能获得它的属性,而不能修改它的属性。因此,可以简单地在构造器,设置值对象的校验,这保证了任意可以被创建的值对象都是有效的。
type Money struct{
amount int//数量
currency int//单位
}
func NewMoney(amount int,currency int) Money{
if amount < 0{
Throw(1,"数量不能为负数")
}
return Money{
amount:amount,
currency:currency,
}
}
func (this *Money) GetAmount() amount{
return amount
}
func (this *Money) Add(money2 Money) Money{
if this.CURRENCY != money2.CURRENCY{
Throw(1,"货币单位不同,不能相加")
}
return Money{
amount:this.amount+money2.amount,
currency:this.currency,
}
}由于值对象修改或者和其他值对象组合时,只能返回一个新的值对象,不能修改原来的值对象。这是值对象的可组合性。
//BankAccount是一个实体,不是值对象
type BankAccount struct{
bankAccountId int
name string
balance Money
}
func go1(){
//初始化一个账号
balance := NewMoney(100,CURRENCY.CNY)
bankAccount := NewBankAccount(10001,"fish",balance)
//如果Money是允许修改的(假设存在SetAmount方法),那么bankAccount就会在不自知的情况下被其他人修改了它的balance属性
fmt.Println(bankAccount.balance)
balance.SetAmount(200)
fmt.Println(bankAccount.balance)
//如果Money是不允许修改的,只有在bankAccount已知的情况下才能修改它的balance属性
fmt.Println(bankAccount.balance)
bankAccount.balance = bankAccount.balance.Add(NewMoney(200,CURRENCY.CNY))
fmt.Println(bankAccount.balance)
}为什么要这样设定,因为值对象作为没有身份的领域概念,它的领域概念是通过它的属性来表达。如果值对象能被修改,引用它的实体对象就可能在不自知的情况下被修改了。从上面的BankAccount实体和Balance值对象就可以看出来了。
15.3 具有行为和领域内聚性
你可以不用Money这样的值对象,而直接在BankAccount实体中使用两个基础属性,amount属性与currency属性。但是这样做会有问题:
- 丢失了领域概念,Money表达了一个领域概念,并且封装了它的职责(方法)。如果BankAccount自己直接用属性的话,会让BankAccount的逻辑很重,而且有Money相加的重复代码。
- 丢失了验证行为,Money作为领域概念,有amount属性不能为负数的领域要求,如果由BankAccount自己直接用属性的话,就会有amount属性不能为负数的重复代码。
因此,值对象最重要的意义在于,它代表了一个领域概念,有自己的职责和边界。
15.4 自验证
这个很显然了,由于值对象都是一旦创建就不能改变了,所以对值对象的校验仅需要在构造函数做一次就足够了。
type Money struct{
amount int//数量
currency int//单位
}
func NewMoney(amount int,currency int) Money{
if amount < 0{
Throw(1,"数量不能为负数")
}
return Money{
amount:amount,
currency:currency,
}
}
//余额Money
type BalanceMoney struct{
Money
}
func NewBalanceMoney(amount int,currency int){
return NewMoney(amount,currency)
}
//工资Money
type SalaryMoney struct{
Money
}
func NewSalaryMoney(amount int,currency int){
if currency != CURRENCY.CNY{
Throw(1,"工资只能用人民币来表达")
}
if amount < 3000{
Throw(1,"工资不能少于3000元")
}
return NewMoney(amount,currency)
}另外,我们可以进一步地表达具体领域的值对象,例如工资是不能超过3000元的,而且只能用人民币来发放。所以有了继承了Money的SalaryMoney的值对象。
15.5 扩展用法
15.5.1 静态工厂
func NewMoney(amount int,currency int) Money{
if amount < 0{
Throw(1,"数量不能为负数")
}
return Money{
amount:amount,
currency:currency,
}
}
type NewCNYMoney(amount int)Money{
return NewMoney(amount,CURRENCY.CNY)
}由于构造器不只一个,我们可以创造一些方便使用的构造器方法,以简化使用。这称为静态工厂。
15.5.2 微类型
func NewPost(formId int,userId int,title int)Post{
//。。。。
}
func go1(){
//正确调用方法
userId := 10001
formId := 20001
post := NewPost(formId,userId,"123")
//错误调用,但依然会编译通过
post := NewPost(userId,formId,"123")
}由于很多接口都是使用int和string的基元类型,这使得它们有可能会被调用时,参数顺序错了仍然会编译成功。
type FormId int
type UserId int
func NewPost(formId FormId,userId UserId,title int)Post{
//。。。。
}
func go1(){
//正确调用方法
userId := UserId(10001)
formId := FormId(20001)
post := NewPost(formId,userId,"123")
//错误调用,编译不通过
post := NewPost(userId,formId,"123")
}一种方法是使用微类型,对基元类型封装,避免这种问题。但是这会让类型系统复杂一点,不是DDD的一般推荐性用法。
16 实体
16.1 具有身份
实体是具有身份的领域概念,而身份一般就是使用id来描述。不同的实体,只要id相同,就可以认为它们就是相同的领域对象。例如,人,书本,订单这些领域概念。
16.2 自验证和不变条件
type Recipe struct{
title string
steps []RecipeStep
}
func NewRecipe(title string, steps []RecipeStep) Recipe{
if len(title) == 0{
Throw(1,"标题不能为空")
}
if len(steps) == 0{
Throw(1,"步骤不能为空")
}
return Recipe{
title:title,
steps:steps,
}
}可以在构造函数里面设置验证,确保实体满足其不变条件
type Recipe struct{
title string
steps []RecipeStep
isPublish bool
}
func (this *Recipe) Publish(){
if this.isPublish == true{
Throw(1,"已经发布过了")
}
this.isPublish = true
}
func (this *Recipe) SetSteps(steps []RecipeStep){
if this.isPublish{
Throw(1,"发布后不能再修改步骤")
}
this.steps = steps
}实体没有值对象的不可变特性,但是依然只能提供可读属性。修改属性的方法必须由实体的行为来提供,行为由业务逻辑来决定。在行为里面,我们可以加入自验证的业务逻辑,例如已经发布的食谱不能修改步骤。
16.3 具有行为
实体自身包含行为,并且行为本身可以委派一部分给值对象来实现。这让实体只去实现必要的业务逻辑,不需要为验证值对象来烦恼。
16.4 避免不确定行为
type Recipe struct{
title string
steps []RecipeStep
isPublish bool
publishTime time.Time
}
func (this *Recipe) Publish(publishTime time.Time){
if this.isPublish == true{
Throw(1,"已经发布过了")
}
this.publishTime = publishTime
this.isPublish = true
}尽量让实体是确定性的,可测试的,让它的状态仅依赖于外部的输入。例如,发布时间由外部传入,而不是取内部的当前时间。
16.5 禁止公开设置器,和使用备忘器模式
type Comment struct{
postId int
commentId int
floor int
userId int
content string
}
type Post struct{
postId int
floor int
}
func (this *Post) AddComment(userId int,content string) Comment{
floor := this.floor
this.floor = this.floor + 1
return Comment{
postId:this.postId,
commentId:UUID(),
floor:floor,
userId:userId,
content:content
}
}帖子下面的评论,评论的楼层号是由Post实体自己维护的,不能由提供公开设置器来设置,因为这样会破坏floor的领域特性,floor总是递增的。与此同时,floor是私有变量,怎样让持久化层存取呢?
type PostSnapShot struct{
PostId int
Floor int
}
func (this *Post) GetSnapShot()PostSnapShot{
return PostSnapShot{
PostId:this.postId,
Floor:this.floor,
}
}通过备忘录模式来解决
16.6 尽量建模为值对象,而不是实体
type OrderProduct struct{
productId int
price Decimal
amount Decimal
total Decimal
}
type Order struct{
orderId int
products []OrderProduct
}对于订单下的每个商品,就不需要建模为实体对象,而是应该建模为值对象。因为,OrderProduct脱离了Order是没有意义的,它也是没有身份的。注意,商品是有身份的对象,应该创建为实体,但订单项不是商品,它仅仅表示了订单里面包含了哪些商品的这个信息。
而且,进一步地,OrderProduct应该附带了商品的标题和规格等信息,以方便在UI展示,不需要对Product进行join操作,而且从逻辑上也是如此,因为订单项反映的是下单时的商品名称,而不是最新的商品名称。
16.7 身份ID确定
16.7.1 自然键
func NewBook(isbn string)Book{
return Book{
id:isbn,
}
}使用外部传入的自然键作为id,这种用法比较少,还要考虑可能的扩展性问题。例如,开始用户系统只有微信用户时,使用微信openid作为id键,但是当用户系统扩展到手机注册,QQ注册时,就会产生无法扩展的问题,这个时候改为自己系统生成id更为合理。
16.7.2 数据存储生成id
func addPost() {
//在存储库获取form对象
forum := this.formRepo.Get(formId)
//在内存中生成帖子
post := form.AddPost(postTitle, postDesc)
//但是生成的帖子的id,需要插入到数据库以后才能获得
postId := this.postRepo.Add(post)
//这导致了置顶的业务操作,放进不了三步流程的中间一步
post.SetId(postId)
post.SetTopPlace()
this.postReop.Save(post)
}关系式数据库都有提供自增id作为键的方式,但这种方式会破坏三步流程,不太建议使用。另外一个问题是,自增id容易让外部猜测到业务的数据量,对于敏感的用户id,订单id,帖子id,这些都是不能用自增作为id的。
type Post struct {
PostId int
Title string
Desc string
IsTop bool
}
func (this *Post) SetTopPlace() {
this.IsTop = true
}
type Form struct{}
func getNextPostId() int {
rows := this.db.Select("select id from t_serial where name = ? for update", "post")
id := rows.GetData(0)
this.db.Update("update t_serial set id = ? where name = ?", id+1, "post")
return id
}
func (this *Form) AddPost(postTitle string, postDesc string) Post {
return Post{
PostId: getNextPostId(),
Title: postTitle,
Desc: postDesc,
IsTop: false,
}
}
func addPost() {
//在存储库获取form对象
forum := this.formRepo.Get(formId)
//在内存中生成帖子,并且执行置顶操作
post := form.AddPost(postTitle, postDesc)
post.SetTopPlace()
//帖子写入到存储库
this.postReop.Save(post)
}使用数据存储生成id的方法,应该用单独的表来做键id生成,这样能避免破坏三步流程。并且单独表做id生成,能灵活地生成如日期+id的格式。
16.7.3 内存生成id
func (this *Form) AddPost(postTitle string, postDesc string) Post {
return Post{
PostId: GUID(),
Title: postTitle,
Desc: postDesc,
IsTop: false,
}
}另外一种方法是使用GUID等方法生成id,避免破坏三步流程,而且避免泄漏数据量,但是,id不是趋向自增的,对于数据库来说,插入性能下降会很多。
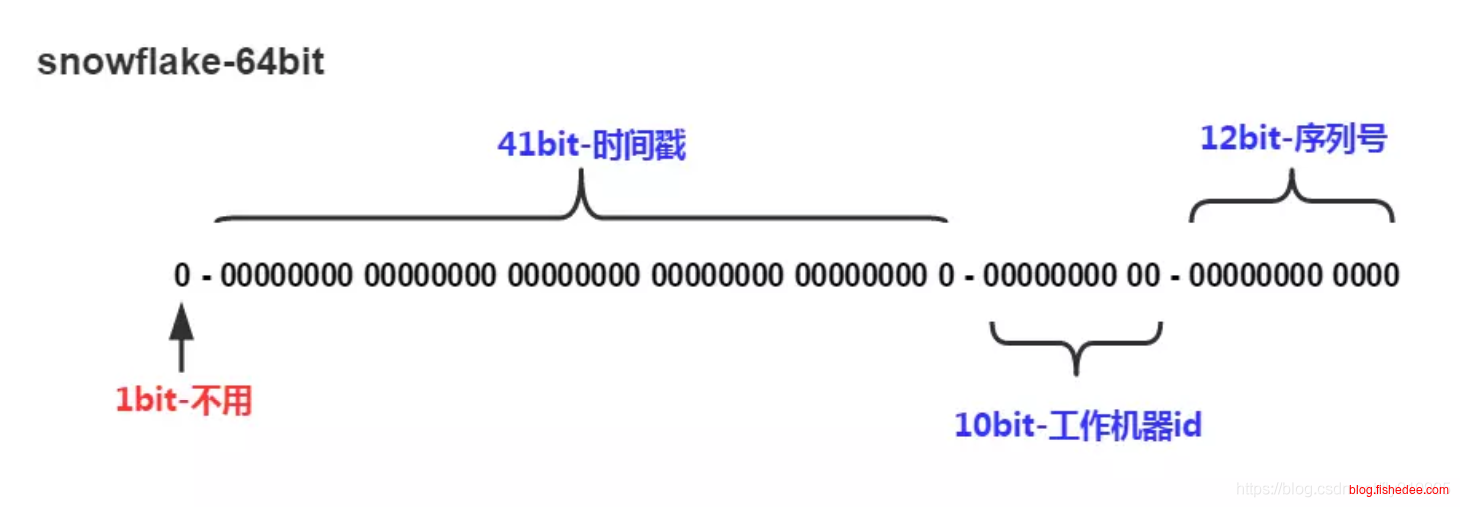
另外一种方法,是使用Snowflake等方法来生成趋向自增的id,也是很好的
func (this *Form) AddPost(postTitle string, postDesc string,userId int,createTime time.Time) Post {
postId := fmt.Sprintf("%v-%v-%v",createTime,userId,Math.Rand(100))
return Post{
PostId: postId,
Title: postTitle,
Desc: postDesc,
IsTop: false,
}
}最后一种方法是综合考虑字段的业务特性,组合id。这种方法进一步考虑了id需要在后端数据库分区的问题,由于postId中包含了userId,所以不需要查询数据库仅从postId就能知道它的userId,同时后端post数据是根据userId分区到不同的数据表上的,所以根据postId就能直接定位到具体的表了,这是相对复杂和周全的设计了。
17 领域服务
17.1 无状态
领域服务也是一个领域概念,它表达的是一种领域概念,但它是没有属性,没有状态的。例如,运输成本计算器,满减规则,优惠券排斥规则,汇率转换计算器等等。而对应的,实体和值对象是有状态的,领域服务的输入是领域实体或者值对象,输出是领域输出的结果。
注意,它和应用服务的不同,应用服务是将领域逻辑与技术逻辑编排在一起的代码,领域服务仅仅包含领域逻辑,它表达的是一个显式的领域概念。所以,不要在领域服务中包含权限检验,登录态校验的逻辑。
17.2 意义
领域服务有两种使用的场景
17.2.1 封装业务策略与过程
type RecipeHotCalcualte struct{
}
func (this *RecipeHotCalcualte) Calcuate(recipe Recipe) int{
return recipe.GetVisitNum() * 10 + recipe.GetCollectNum()
}热度计算器就是一种领域概念
17.2.2 表示策略的约定
type CurrencyChanger interface{
Convert(fromMoney Money,targetCurrency Currency) Money
}CurrencyChanger是一个外汇货币计算器,可以将特定的货币转换为其他货币。由于这个外汇货币计算器是调用外部的实时汇率来计算的,它涉及到了具体的技术复杂度。所以,领域层仅包含了这个计算器的接口约定,而这个接口的具体实现由基础设施层来提供。另外,将这个服务设计为接口的方式,提供了单元测试的mock实现的可能。
17.3 领域服务层与实体依赖
func Transfer(fromUserId int ,toUserId int,money Money){
fromAccount := AccountRepo.Get(fromUserId)
toAccount := AccountRepo.Get(toUserId)
fromMoney := CurrencyChanger.Convert(money,fromAccount.GetCurrency())
toMoney := CurrencyChanger.Convert(money,toAccount.GetCurrency())
fromAccount.Redraw(fromMoney)
toAccount.Deposit(toMoney)
AccountRepo.Save(fromAccount)
AccountRepo.Save(toAccount)
} 领域服务层最为简单的使用是,在应用服务层直接调用
type Recipe struct{
hotCalcualteService RecipeHotCalcualte
}
func (this *Recipe) RefreshHot(){
this.hotNum = this.hotCalcualteService.Calcuate(this)
}较为麻烦的是,领域服务被实体所依赖的情况,例如以上这种
func NewRecipe(title string,steps []RecipeStep,hotCalcualteService RecipeHotCalcualte)Recipe{
return Recipe{
title:title,
steps:steps,
hotCalcualteService:hotCalcualteService,
}
}由于创建Recipe实体需要RecipeHotCalcualte参数,所以构造器的参数比较丑陋,不能被依赖自动注入
17.3.1 工厂模式
type RecipeFactory struct{
hotCalcualteService RecipeHotCalcualte
}
func (this *RecipeFactory) NewRecipe(title string,steps []RecipeStep)Recipe{
return Recipe{
title:title,
steps:steps,
hotCalcualteService:this.hotCalcualteService,
}
}
func go1(){
recipe := this.recipeFactory.NewRecipe(title,nil)
}第一种方法是让创建Recipe的过程成为一个类的方法,而不是类的构造器。这个类成为工厂,工厂预先注入hotCalcualteService参数,这样创建Recipe的时候就不再需要传递hotCalcualteService参数了。
17.3.2 ORM与依赖注入
func go1(){
recipe := RecipeRepo.Get(10001)
}但是有些时候,创建Recipe不是手动创建,而是在存储库提取出来的,这意味着要让存储库知道在哪里找到这个hotCalcualteService参数。
type RecipeRepo struct{
hotCalcualteService RecipeHotCalcualte
}
func (this *RecipeRepo) Get(recipeId int)Recipe{
//select数据,取出recipe,并自动填充参数
//手动填写注入参数
recipe.SetHotCalcualteService(this.hotCalcualteService)
}较为繁琐的方案是,在存储库手动注入。
另外一个方案,是让ORM支持依赖注入,这就比较限制ORM框架的支持了。
18 领域事件
领域事件这个说得比较多了,主要补充的是,领域事件如何在细节上实现它,有几种方法:
- 线程级同步队列,发布消息时直接回调本地方法,由于是同步执行的,这保证了消息的发布与执行在同一个事务内。但是这样做违反了事件存储使用最终一致性的初衷。
- 内存事件存储,将事件写入实体的一个固定变量,然后由应用服务层写入数据库。这样比较繁琐,需要应用服务层显式支持,但单元测试很好做。
- 线程级写入数据库,将事件写入到数据库的固定表上,简单方便,应用服务层无参与,推荐做法。唯一缺点是,定时器扫描固定表后批量发送给消息中间件,延迟比较大。
- 线程级写入消息中间件,将事件直接写入消息中间件,这样需要消息中间件提供2PC,或者事务消息的支持,不然可能会丢失消息。
19 聚合
19.1 并发隔离下的一致性
type Order struct{
Coupons []int
Total decimal
}
type OrderProduct struct{
OrderId int
OrderProductId int
Price decimal
Amount decimal
Total decimal
}我们假设有一个订单实体,和订单项的值对象。然后在同一个时刻,用户对他的订单执行两个操作:
- 对订单使用满300减50的优惠券
- 删除一个订单项
| A操作 | B操作 |
|---|---|
| 获取订单总额为320,select total from t_order where orderId = 100 | |
| 获取订单总额也为320,select total from t_order where orderId = 100 | |
| 满足优惠券条件,update t_order set total = total-50 where orderId = 100 | |
| 删除一个订单项,delete from t_order_product where orderProductId = 200 and orderId = 100 | |
| 更新订单总额,update t_order set total = total-70 where orderId = 100 |
好了,我们产生一个不一致的问题。由于原来的订单只有两个订单项,一个商品为70元,另外一个商品为250元。只有这两个商品都在订单里面的时候,才能使用优惠券。但是在并发的条件下,产生了不一致,只有一个商品为250元的订单,却能使用优惠券,总单只需要200元。
解决这个方法,很显然,能用数据库的select for update…来加锁。但是,我们也能使用聚合来实现。
19.2 领域对象集
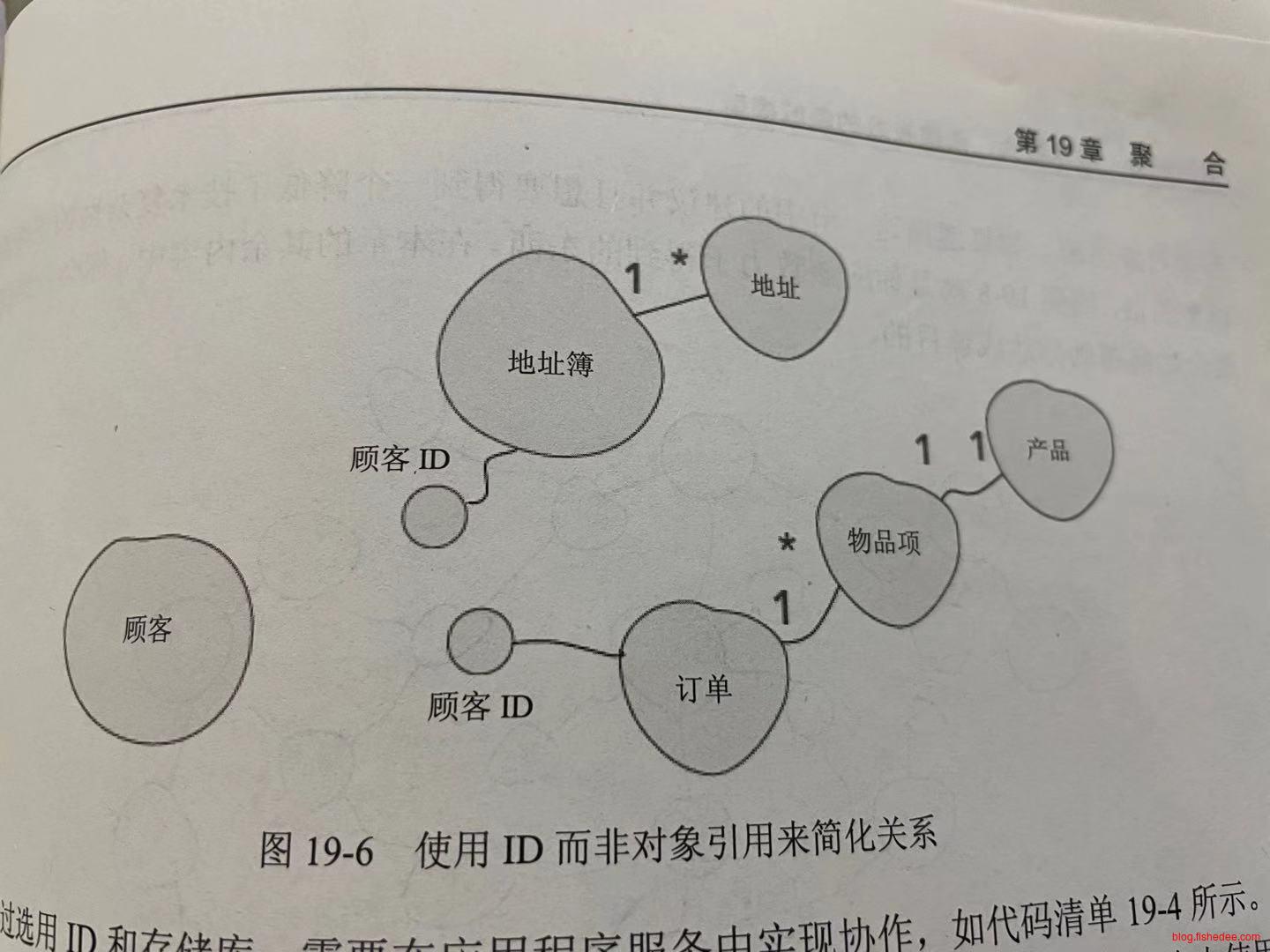
type OrderProduct struct{
price decimal
amount decimal
total decimal
}
type Order struct{
products []OrderProduct
coupons []int
total decimal
}聚合的想法将多个有业务一致性和不变性的领域对象(实体或者值对象)合并成一个大的领域对象,称为聚合。就像,订单项和订单,应该合并为一个大的订单结构。
type OrderRepo interface{
Get(orderId int) Order
Save(order Order)
}然后,存储库现在只能从将整个聚合读取或者存储,不能仅读取或者存储聚合的一部分。
type Order struct{
products []OrderProduct
coupons []int
total decimal
}
func (this *Order) DelProduct(){
//删除最后一个订单项
this.products = this.products[0:len(this.products)-1]
for _,product := this.products{
this.total += product.total
}
}
func (this *Order) UseCoupon(){
//满300减50
if this.total > 300{
this.total = this.total - 50
}
}对聚合的子结构的修改,都必须通过聚合根部的方法来执行。例如,对订单项OrderProduct的删除,都必须通过Order的方法DelProduct来执行。
| A操作 | B操作 |
|---|---|
| 获取订单总额为320,OrderRepo.Get(100) | |
| 获取订单总额也为320,OrderRepo.Get(100) | |
| 满足优惠券条件,order.UseCoupon() | |
| 删除一个订单项,order.DelProduct() | |
| 保存订单,OrderRepo.Save(order) | |
| 保存订单,OrderRepo.Save(order) |
那么,在并发条件下,我们依然得到了一个可靠的并发一致的订单结构。例如,在如上的并发环境下,用户最多会发现,要么是优惠券使用了,同时删除了的订单项重新出现了。要么是,订单项删除了,优惠券的效果又消失了。不可能会出现,订单项既消失了,优惠券的效果又使用了的不一致情况。这种方法真的很奇妙,它在应用层减缓了并发冲突的问题。
但是,这种方法的缺陷在于会让更新丢失,在并发冲突的环境下,另外一个并发产生的影响好像凭空消失了。如果要让用户的体验最好,还是得加上数据库的for update操作。
type UserInfo struct{
UserId int
Age int
GuardianPhone string
}但这种方法并不是没有价值,例如,用户信息栏在年龄字段低于18岁的时候,必须设定监控人手机号的信息。使用更新丢失的方法是没有问题。但是采用无锁的更新操作时就可能产生不一致的并发冲突问题,出现一个用户信息既是低于18岁,也没有设定监护人手机号的问题。
19.3 聚合的选择
选择什么领域对象组合为一个聚合是技巧性的工作,我们的原则是尽可能使用小聚合。因为,聚合越大,在存储库读取的数据就越大,这会产生巨大的内存占用,和往返网络数据延迟。这是一些指导原则:
- 切分没有不变性和一致性的领域对象,他们不需要聚合。例如,用户信息,和订单信息就不需要聚合。创建订单时需要检查用户是否存在,但这没有表现出两者之间需要一致性要求。即使用户删除,或者修改信息,订单的信息也不需要变更。同样地,订单删除或者修改信息时,订单也不需要变更。
- 切分允许最终一致性的领域对象,他们不需要聚合。例如,用户余额,和用户余额流水。余额流水删除时,同样地用户余额需要回滚。用户余额变更时,需要增加一条余额流水。这是一个很有迷惑性的一致性要求。但是,我们从没有用例需要删除余额流水的情况,余额流水是仅仅依赖于用户余额的变更而增加记录的,它自身是不可能会失败或者需要回滚的情况。所以,我们完全可以通过,将用户余额,和用户余额流水看成是需要最终一致性的两个实体,它们之间通过消息队列来保证原子性。
- 跨上下文的一致性要求的领域对象,它们无法有效地用聚合来解决。聚合是一个有界上下文的工具,对于跨多个有界上下文仍然需要一致性要求的领域对象,我们只能使用分布式事务来解决。例如,库存余额,与订单。订单创建时,库存需要扣除。同样地,库存不足不能被扣除时,订单应该要被回滚,通知用户订单创建不成功。聚合不能在内存里面同时跨上下文加载两个到内存里,这会破坏上下文领域对象的封装性。值得高兴的是,需要这种的情况很少很少。
但是,在某些场景下不要采用聚合来解决并发问题:
- 关联关系的不变性,因为这样的聚合太大了。例如,商品和商品分类,商品只有在商品分类存在的时候才能设置,分类只有没有商品关联该分类的时候才能删除。如果将商品分类为聚合根,获取整个商品,能解决这个问题。但是,显然这样的聚合太大了。因此只能将问题推给数据库来做,设置商品分类时,要对分类进行for update操作。删除分类时,先对该分类for update操作,再去检查是否有商品关联该分类。
19.4 聚合的使用
聚合使用的时候,它们需要满足以下原则:
- 只有聚合根有全局id,子结构不需要全局id,只需要局部id就可以了。
- 外部的其他聚合根,只能引用这个聚合根的全局id,不能引用子结构的id。
- 对聚合子结构及根结构的任意修改,但只能通过聚合根方法来操作,不能取出子结构来修改。
19.5 聚合的数据量太大
//每个库存批次的单价和数量
type StockRemain struct{
materialId int
price decimal
amount decimal
}
//总库存批次的总数量,和加权单价
type Stock struct{
remains []StockRemain
materialId int
price decimal
amount decimal
}有些时候,聚合的设计,子结构的数据量太多,加载时需要的内存太大,怎么办?例如,我有一个库存余额,和库存批次的聚合。由于历史的材料批次太多了,所以加载某个材料的库存时占用内存超级大。
19.5.1 忽略它
在早期应用开发阶段,不要对这些细节问题优化,请忽略它。早期应用开发阶段,产品方向是否正确,功能是否产生预期价值是更重要的考虑。
19.5.2 延迟加载
Hibernate框架提供了延迟加载的功能,加载stock时,它的remain字段都是一个虚拟的proxy对象。只有开发者调用了这个对象的方法时,Hibernate才去数据库获取stockRemain的详细信息并生成一个真实对象代替这个proxy,这个方法称为延迟加载对象。
但是,这样真的很烂。因为子结构有1000个时,就要调用1000次的select操作,这个称为n+1问题。强烈不要使用这个方法
19.5.3 存储库按用例加载
type StockRepo interface{
GetWithRemain(stockId int,stockRemainId int)Stock
GetWithAmount(stockId int)Stock
}按照用例加载仅填充一部分用例的Stock聚合。例如,如果我们加载Stock是为了减少某个批次的材料,那么这个Stock对象就不需要整个加载了,只加载含有一个批次材料的Stock聚合就可以了。这种方法对于StockRepo的改造较大,而且不支持聚合的批量操作。
func go1(){
stock := StockRepo.Get(10001)
//减少批次20001的100数量
stock.DecreaseRemain(20001,100)
//增加批次20002的200数量
stock.IncreaseRemain(20002,200)
StockRepo.Save(stock)
}原来的方法可以一次加载一个stock,在内存批量对stock进行修改后一次写回。但现在就不行了。因为存储库加载的stock聚合仅包含了一个批次的材料。所以,这种方法也不太建议。
19.5.4 实体嵌套存储库
type Stock struct{
remains []StockRemain
materialId int
price decimal
amount decimal
}
func (this *Stock) DecreaseRemain(stockRemainId int, amount int){
//检查内存是否包含这个批次,没有的话到存储库读取
if remains.Has(stockRemainId) == false{
remains.Add(stockRepo.GetMaterial(stockRemainId))
}
//普通业务逻辑
}
func (this *Stock) DecreaseRemainBatch(stockRemainIds []int, amount int){
//检查内存是否包含这个批次,没有的话到存储库读取
if remains.Has(stockRemainIds) == false{
//这是区分延迟加载的地方,允许按照用例批量加载子结构
result := stockRepo.GetMaterialBatch(stockRemainIds)
for _,stockRemain := range result{
remains.Add(stockRemain)
}
}
//普通业务逻辑
}打破领域对象不能包含存储库的规则,领域对象的方法里面按需加载子结构。这样对使用方透明,而且支持聚合的批量操作。这种方法不失为一种折中的,改动也很少的方法。
19.5.5 分拆
进一步将聚合拆分为小聚合,例如只对库存批次做聚合,而库存总额就是另外一个聚合。库存总额根据库存批次的变化来最终一致性更新。这是改动最大,使用方复杂度最高,但性能效果最好的方法。
19.6 存储库与聚合
存储库与聚合的一些指导原则:
- 仅能让储存库对聚合存取,不能对聚合子结构存取
- 删除聚合时,把整个聚合子结构都删除
- 同一个事务下的同一个id下的聚合应该是缓存起来的,这样避免内存在有两个不同位置的对象对应同一个数据行的问题。Hibernate和JPA这类专业的ORM有一级缓存来保证避免这个问题。
- 避免使用延迟加载。
19.7 并发控制
综合起来,并发有几种方式:
- 不解决,这种方式比较危险,如果系统数据要求不高,允许少量不一致,也是可以接受的。
- 聚合,解决了并发一致的问题,但是可能会有丢失更新。这种方式隐含了最后写入者胜的并发冲突解决方式。
- 数据库的悲观锁,使用数据库内含的悲观锁机制(for update),对涉及的读数据进行加锁,能有效解决所有并发问题,但是锁会造成并发量少,而且对数据库资源的占用大。
- 数据库的乐观锁,使用数据库内含的乐观锁机制(pg在commit时检查行的版本号),没有锁,但是当检测到并发冲突时会报错,需要应用层的重试机制。而悲观锁是不需要应用层重试的,但它可能死锁。
- 应用层的乐观锁,在应用层加入version字段,来解决交互式的并发冲突问题。例如,A用户对一个订单修改时,B用户也对该订单修改了,但A用户的页面仍然是旧数据,这是交互式的并发冲突问题。A用户提交的时候,应用层应该提醒它页面数据已经提交,请重新刷新后提交。解决方法是在数据上加入version字段,version在每次修改数据后都更改为一个GUID值,注意不要用自增数值,因为自增可以由前端来修改。另外一个更为简单的方式是检查modifyTime字段,不需要增加version字段也能实现类似需求,但是并发环境激烈的情况下有漏检的问题。
20 工厂
DDD的工厂就是为了隐藏创建对象的复杂性
20.1 隐藏创建对象的部分参数
type BankAcountFactory struct{
taxChangerService TaxChangerService
}
func (this *BankAcountFactory) NewAccount(accountId int,balance int){
return NewAccount(accountId,balance,this.taxChangerService)
}隐藏了Account的taxChangerService入参
type Forum struct{
tenantId int
forumId int
}
func (this *Form) AddPost(userId int,title string)Post{
return NewPost(this.tenantId,this.forumId,userId,title)
}有些工厂是以类型的方法来提供的,例如NewPost。因此,这个工厂能隐藏tenantId和forumId的两个入参。
20.2 隐藏具体实现
type TaxChangerServiceFactory struct{
}
func (this *TaxChangerServiceFactory) GetTaxChanger(countryCode int){
if countryCode == 86{
return NewChinaTaxChangerService();
}else{
return NewOtherCountryChanagerService();
}
}有时候,工厂是为了隐藏不同实参的具体实现类型。例如要获取不同国家下的税收计算服务。
21 存储库
存储库就是负责技术复杂性的地方,它是DDD战术模型的重要部分
21.1 聚合与存储库的协同
存储库需要读取数据库,然后将参数填入到聚合的字段上。但是聚合的字段都是私有的,怎么填入?由于技术复杂度和业务复杂度分离的原因,存储库与聚合不在同一个包里面的,不能直接读写聚合的字段。
同样地,存储库需要读取聚合字段,然后写入到数据库中。聚合的字段并不是所有都是有公开获取器的,怎么做?
因此,有几种聚合与存储库协同的方式:
- 聚合公开字段设置器和获取器,无奈之举
- 聚合使用备忘录模式,代码很多,但至少保留了领域封装性。看16.5的那一节。
- 存储库使用反射,专业的ORM,如Hibernate和JPA都是这样做的
21.2 反模式
存储器的反模式:
- 不要使用延迟加载
- 不要将存储库用在即席查询和报告。这两类查询应该直接用sql对数据库查询,不要构建领域对象来转换。
22 事件溯源
不要用,没意义
23 UI
6.2.1节已经说过了
24 CQRS
CQRS就是命令和查询使用不同的数据库和业务逻辑来解决,两者不共用的业务逻辑。这是一个相当普遍有效的方法,与事件溯源架构没有任何关系。
24.1 命令端
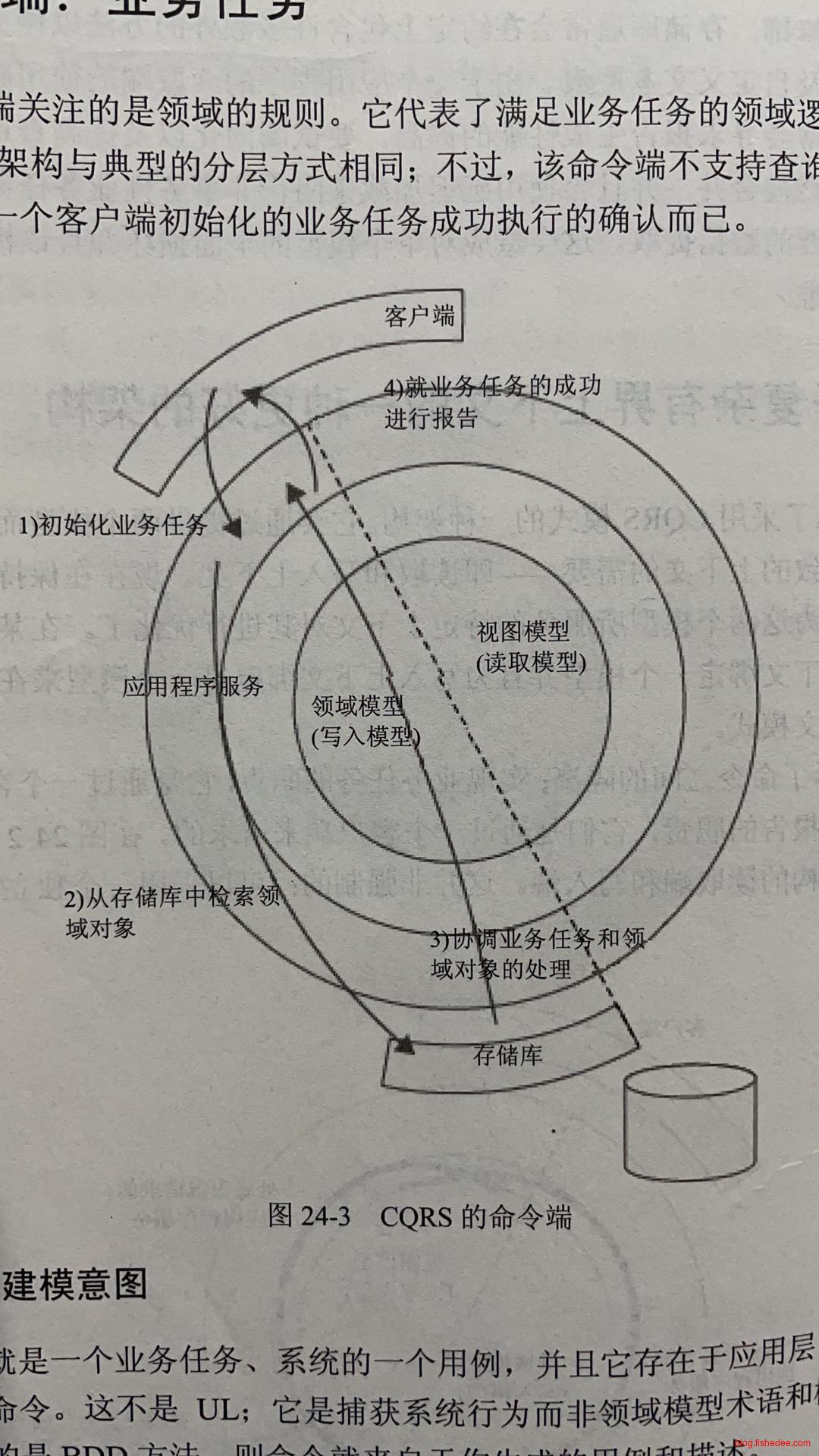
命令端使用DDD的战术模式来实现
24.2 查询端
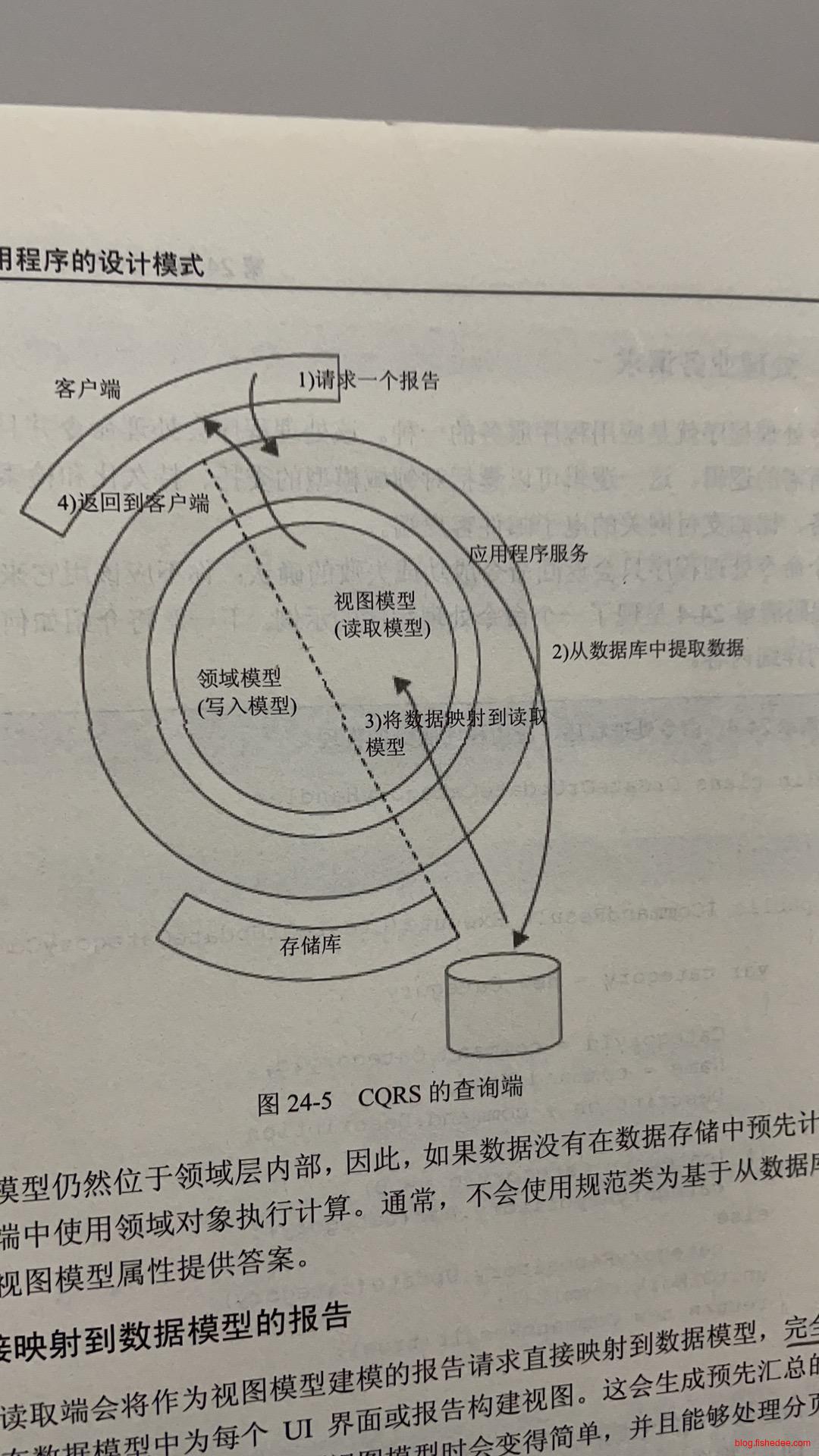
查询端绕过领域模型来提供服务
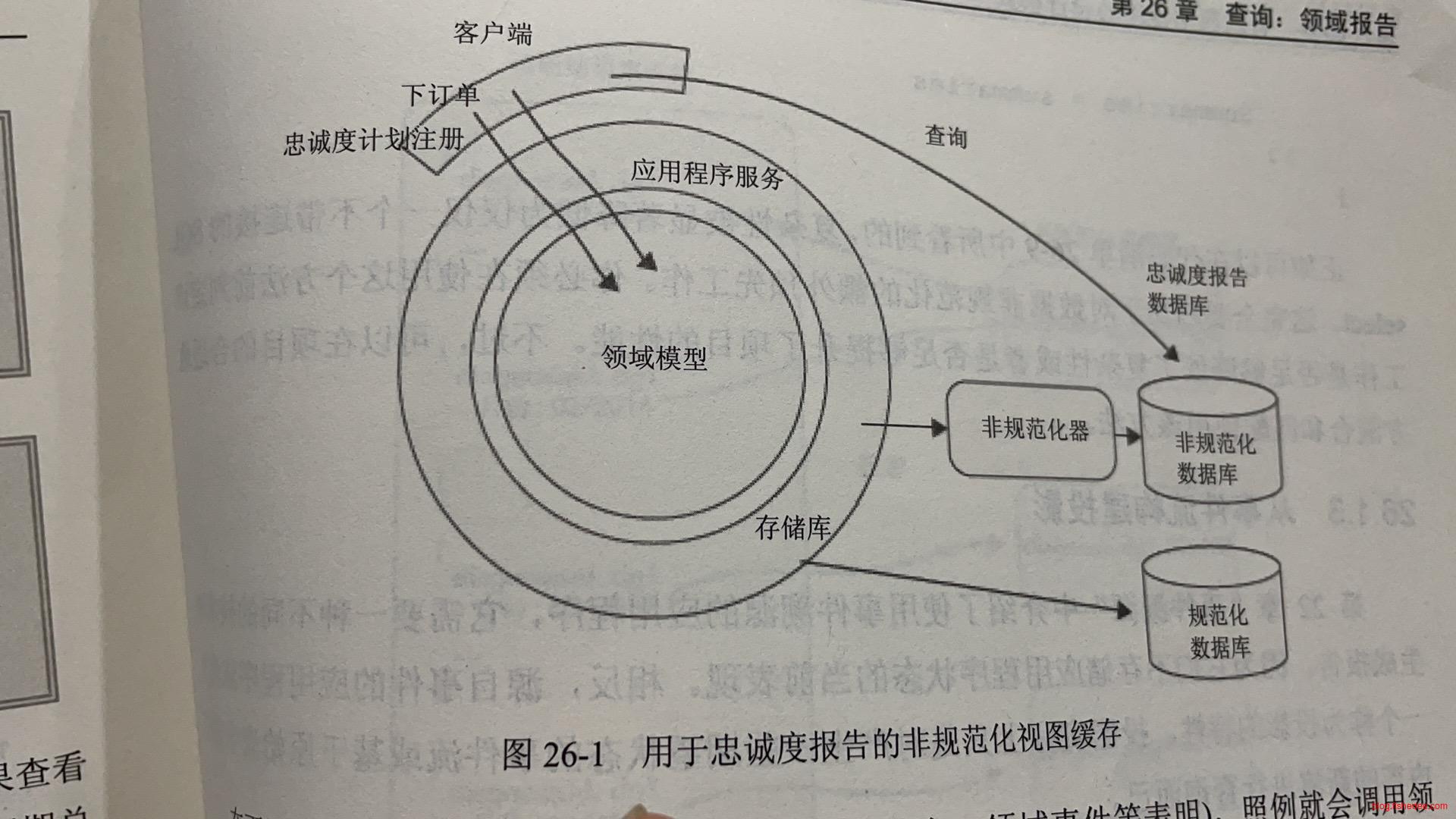
甚至可以依赖领域事件来创建一个非规范化的数据库,为查询做最佳的优化
25 总结
DDD对我来说,真的很重要。它就像原则一样,无论你用的是什么语言,写什么业务,你最终都会遇到它所说的问题,也绕不过最终以它的方法来解决。这可能就是一种软件工程的开发原则和经验吧。
最终回答一下,我读书前遇到的困惑,和用DDD是如何解决的:
- 如何划分系统模块,划分子域,然后用一个上下文对应一个子域来实现它。
- 如何让模块像乐高一样堆起来,每个上下文都是逻辑自治的,用松耦合的方式组合它们。
- 如何做单元测试,三段开发模式从根本上避免了数据库mock,更好地做业务逻辑的单元测试。
- 如何做多表的查询。CQRS提供了使用领域事件来构建非范式化数据,以实现最优化的查询。
- 面向对象编程模式的意义在那里。三段开发模式的第二段就是OOP。
- 事务问题一直依赖于数据库的串行化隔离级别。聚合就是解决这个问题的。
彩蛋有很多有趣的例子,值得一看。
参考资料:
- 架构师如何应对复杂业务场景?领域建模的实战案例解析
- 如何写好业务代码?
- 阿里技术专家详解 DDD 系列- Domain Primitive
- 阿里技术专家详解DDD系列 第二弹 - 应用架构
- 领域驱动设计,盒马技术团队这么做
- 领域驱动设计在互联网业务开发中的实践
- 如何复用一套代码满足多样化的需求?
- 本文作者: fishedee
- 版权声明: 本博客所有文章均采用 CC BY-NC-SA 3.0 CN 许可协议,转载必须注明出处!