0 概述
云效经验汇总
云效是基于最佳实践的CI/CD工具,它相当于整合了以下开源工具
- Jekins
- Gitlab
- Hbase,存放版本化的制品仓库
使用云效的好处在于
- 安全,不受开源工具,特别是开源插件的攻击,发布部署ECS的时候,不需要配置密码,和ssh钥匙。
- 稳定,不需要自建平台,更好更稳定
- 持续更新
- 成本低,不需要维护CI/CD平台
1 Codeup
官网在这里,Codeup相当于对标自建gitlab了。
1.1 导入代码库
没啥好说的,直接用“导入代码库”就能快速导入已有的仓库
1.2 代码组
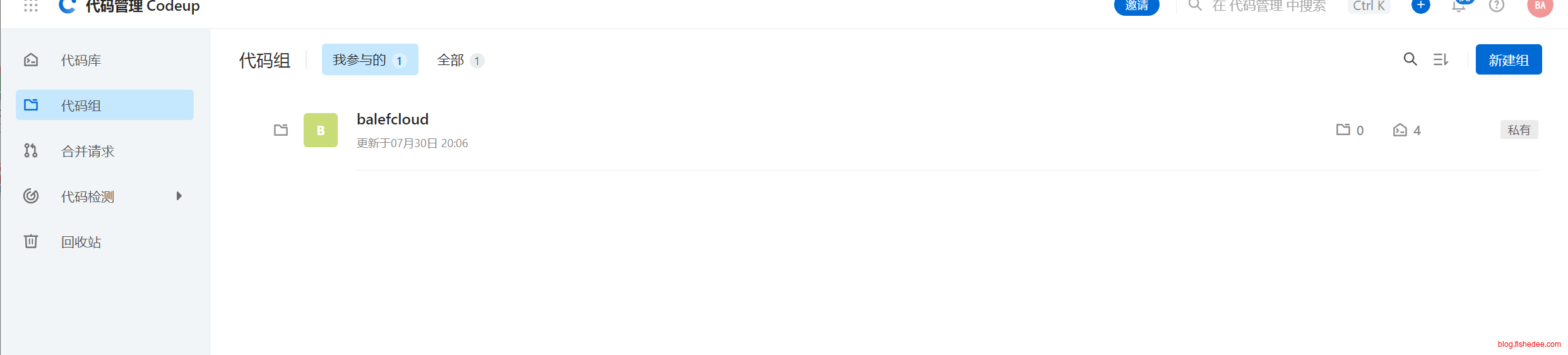
在github中,每个用户都是一个单独的代码组。但是,在一家公司中,允许创建多个代码组,对应多个项目组。每个项目组里面有自己独立的多个成员,和自己独立的多个仓库。
在一个代码组里面,可以进行设置代码组的公开性。这样可以批量设置该代码组下面所有仓库的权限。
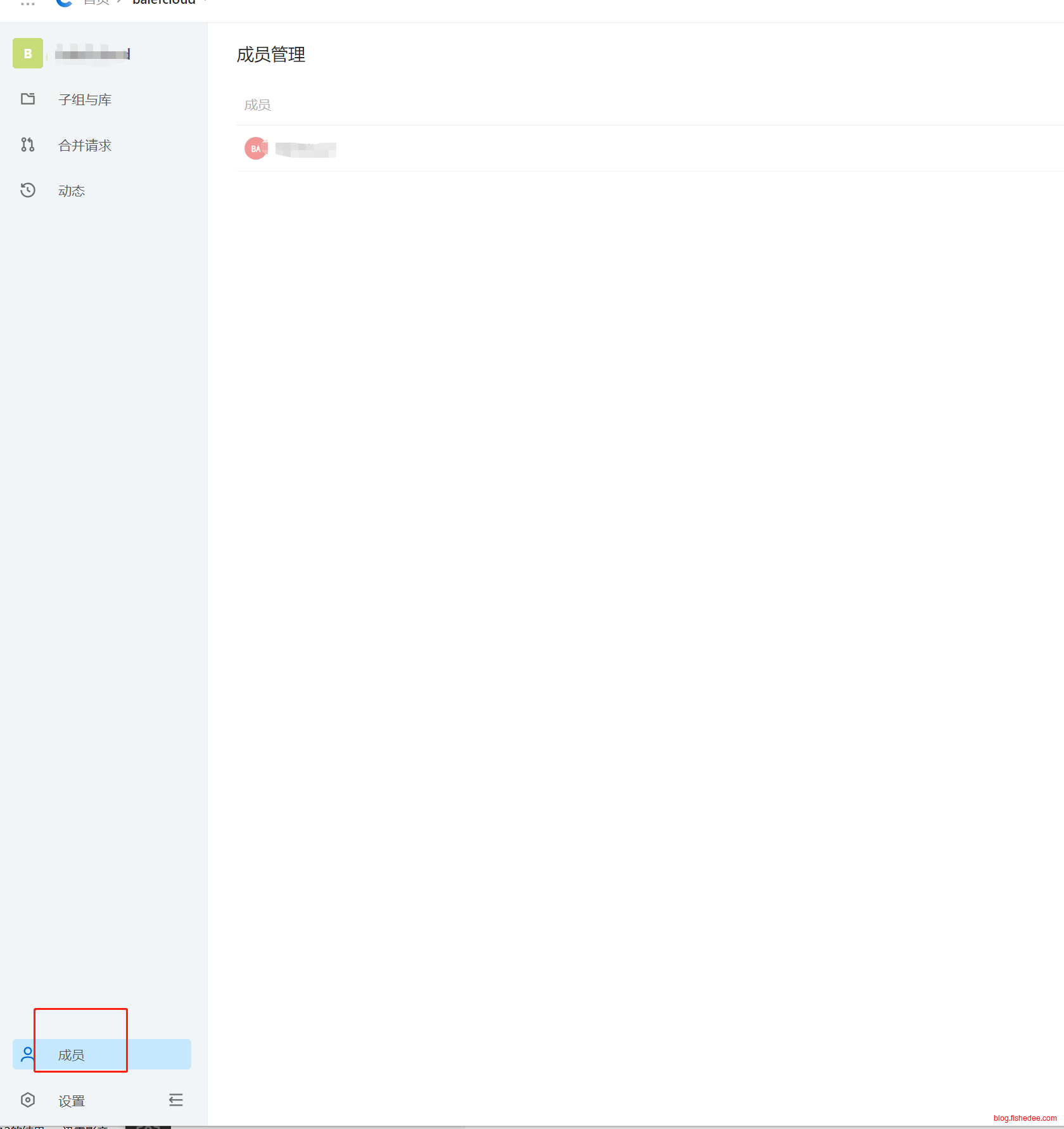
在一个代码组里面,可以设置成员。
在Codeup里面,你甚至可以嵌套代码组,也就是代码组的子代码组。
2 流水线
2.1 概览
流水线是一个复杂的问题,对应的开源工具是Jekins。一个好的持续集成工具需要考虑以下问题:
- 查看日志,在构建和部署的时候,时常需要及时查看日志,而不需要登录到各个机器上看日志。
- 多机部署,对多个机器进行部署,支持分批和全量部署
- 自定义多步骤,可以自由构建自己的步骤,以自定义自己的流水线
- 重试单步骤,在某个步骤失败了,我们可以指定对单个步骤进行重试和恢复,而不总是需要从头开始
- 并行多步骤,对于多个没有依赖关系的步骤,可以进行并行操作,以减少部署和构建时间
- 通知,持续集成的某个流水线,每个步骤成功,或者失败的时候,可以进行外部通知,包括有邮件,钉钉,企业微信,飞书,Webhook等方式的通知。
- 回滚,当发布失败的时候,支持对任意一个历史版本进行回滚,或者下载构建代码包。
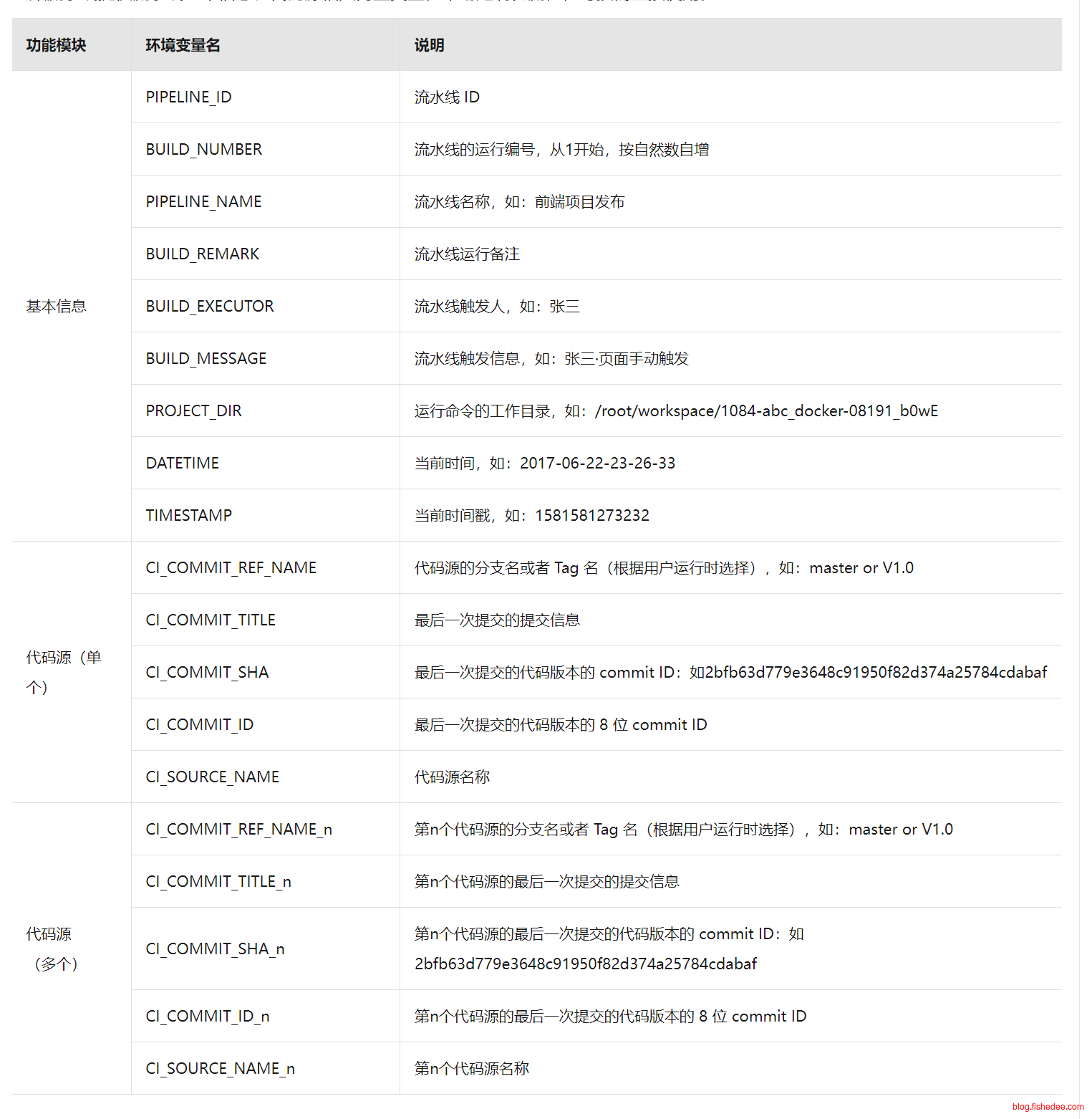
- 触发,支持多种构建方式,包括Webhook触发构建,定时器触发,手动触发
- 变量,变量包括内置变量,自定义变量和通用变量。自定义变量是指在手动触发时可以手动指定的变量,通用变量是指企业级别的全局变量。变量可以在流水线中各个步骤中引用,也可以替换构建文件夹中的代码。
- 人工卡点,构建步骤可以由Webhook自动触发,但是部署的时候,需要经过相关运维人员审核以后才能触发,审核的过程就称为“人工卡点”
参考资料:
2.2 快速入门
官网文档中有一个快速入门的例子
直接参考这个例子就可以了,没啥好说的。我们需要注意的是,持续集成的核心在于两点:
- 构建,从源代码开始构建为一个制品。这里,由flow将制品打包到云端。
- 部署,将制品解压,和启动程序。这里,由flow将制品下载到具体的机器上。
2.2.1 构建的最佳实践
构建步骤的最佳实践是:
- 将构建步骤整理为一个具体的build.sh脚本文件,flow只需要调用build.sh就可以了。
- 在build.sh将所有需要的文件都放入到统一的dist文件夹中
- flow只需要将单个dist文件夹进行打包就可以了。(不要在flow中指定单个文件,也不要在flow中指定多个文件或者多个文件夹)
- 构建物自身应该包含有部署所需的deploy.sh,和其他的nginx, supervisor的配置文件。
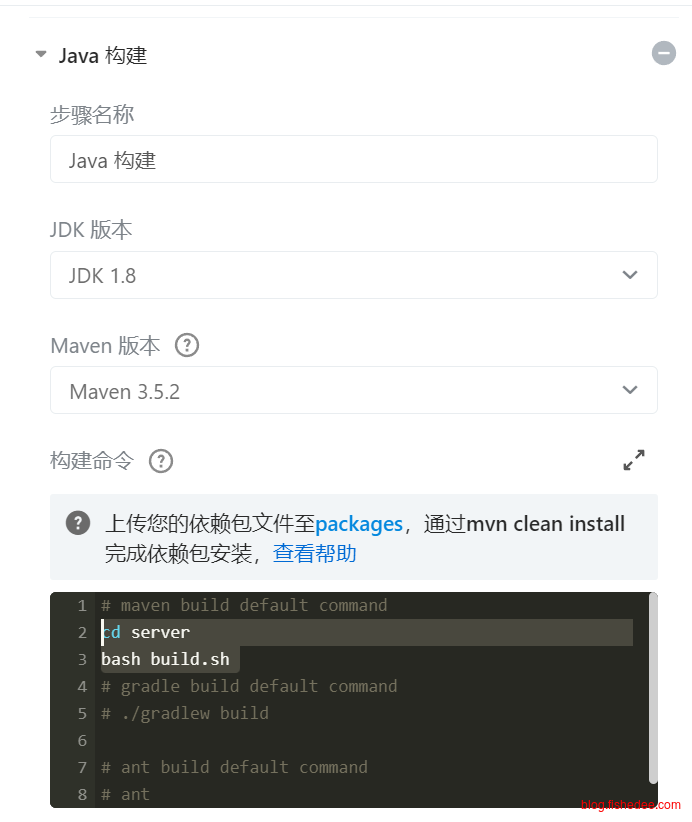
flow 应该配置为简单的build.sh,以最大化自由度
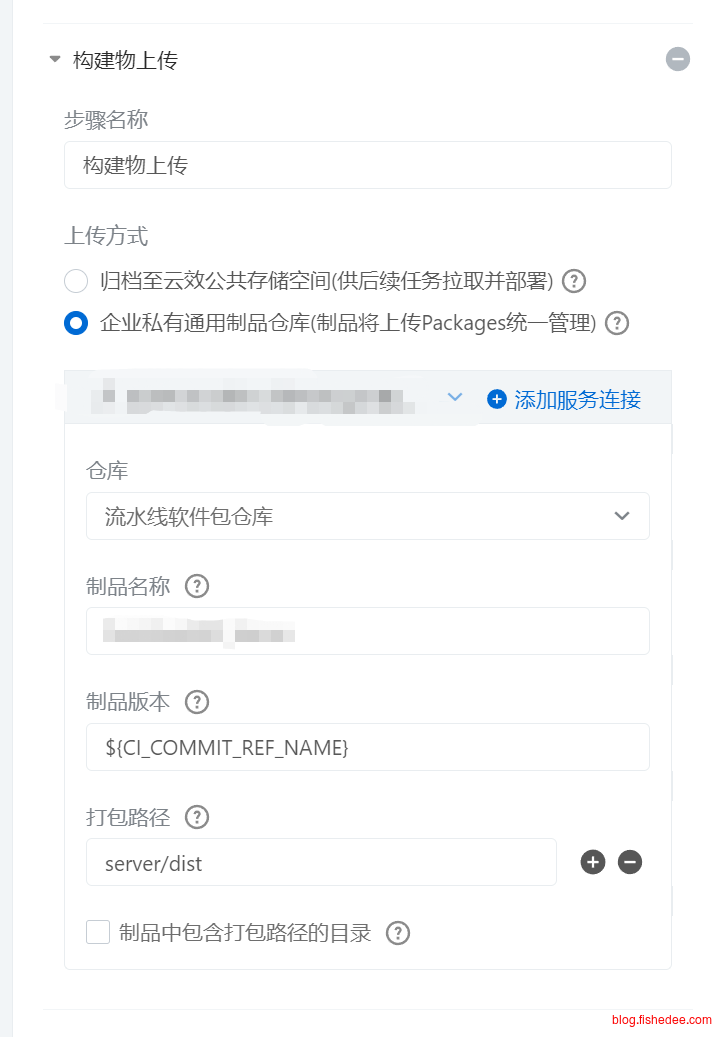
在构建物上传的时候,只指定单个文件夹。这样打包出来的根目录就是内容本身,不含打包路径。
mvn -B clean package -Dmaven.test.skip=true -Dautoconfig.skip
mkdir dist
cp target/xxx.jar dist
cp -r conf/* dist附上一个Java后端典型的build.sh
npm install
npm run prod附上一个前端典型的build.sh
2.2.2 部署的最佳实践
构建步骤的最佳实践是:
- 创建文件夹,解压文件,执行deploy.sh
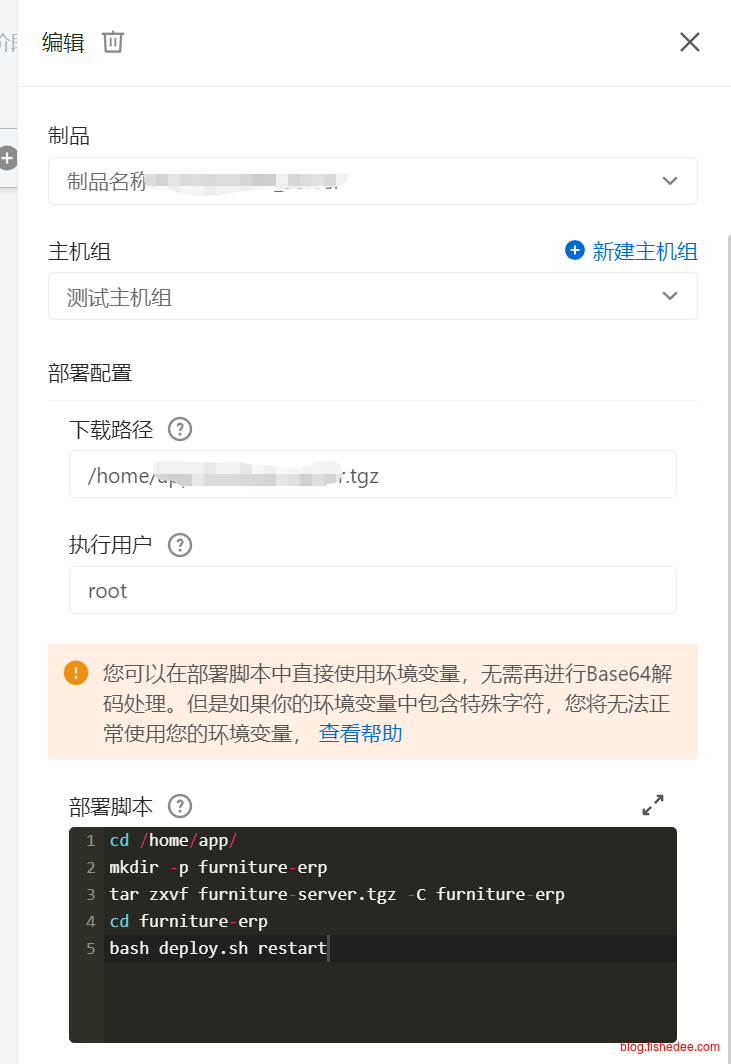
所有的部署脚本由deploy.sh来执行,以最大化自由度
#!/bin/bash
# 修改APP_NAME为云效上的应用名
APP_NAME=myapp
PROG_NAME=$0
USER=jan
ACTION=$1
APP_START_TIMEOUT=20 # 等待应用启动的时间
APP_PORT=9598 # 应用端口
HEALTH_CHECK_URL=http://127.0.0.1:${APP_PORT}/login/islogin # 应用健康检查URL
# 创建supervisor
cp ${APP_NAME}.ini /etc/supervisord.d/${APP_NAME}.ini
supervisorctl update
# 创建出相关目录
mkdir -p log
chown ${USER}:${USER} log
usage() {
echo "Usage: $PROG_NAME {start|stop|restart}"
exit 2
}
health_check() {
exptime=0
echo "checking ${HEALTH_CHECK_URL}"
while true
do
status_code=`/usr/bin/curl -L -o /dev/null --connect-timeout 5 -s -w %{http_code} ${HEALTH_CHECK_URL}`
if [ "$?" != "0" ]; then
echo -n -e "\rapplication not started"
else
echo "code is $status_code"
if [ "$status_code" == "200" ];then
break
fi
fi
sleep 1
((exptime++))
echo -e "\rWait app to pass health check: $exptime..."
if [ $exptime -gt ${APP_START_TIMEOUT} ]; then
echo 'app start failed'
exit 1
fi
done
echo "check ${HEALTH_CHECK_URL} success"
}
start_application() {
echo "starting ${APP_NAME} process"
supervisorctl start ${APP_NAME}
}
stop_application() {
echo "stop ${APP_NAME} process"
supervisorctl stop ${APP_NAME}
}
start() {
start_application
health_check
}
stop() {
stop_application
}
case "$ACTION" in
start)
start
;;
stop)
stop
;;
restart)
stop
start
;;
*)
usage
;;
esac附上一个Java后端典型的deploy.sh,需要做以下事情:
- 创建supervisor的文件
- 创建log文件夹,并赋值用户
- 使用supervisor启动
2.2.3 按照机器的TAG部署
在普通情况下,流水线是与具体的机器IP绑定在一起的,当机器有新增或者减少的时候,都需要修改流水线的步骤。
因此,Flow提供了发布到指定TAG的机器上,从而避免与具体IP耦合在一起。文档在这里
2.3 代码源触发
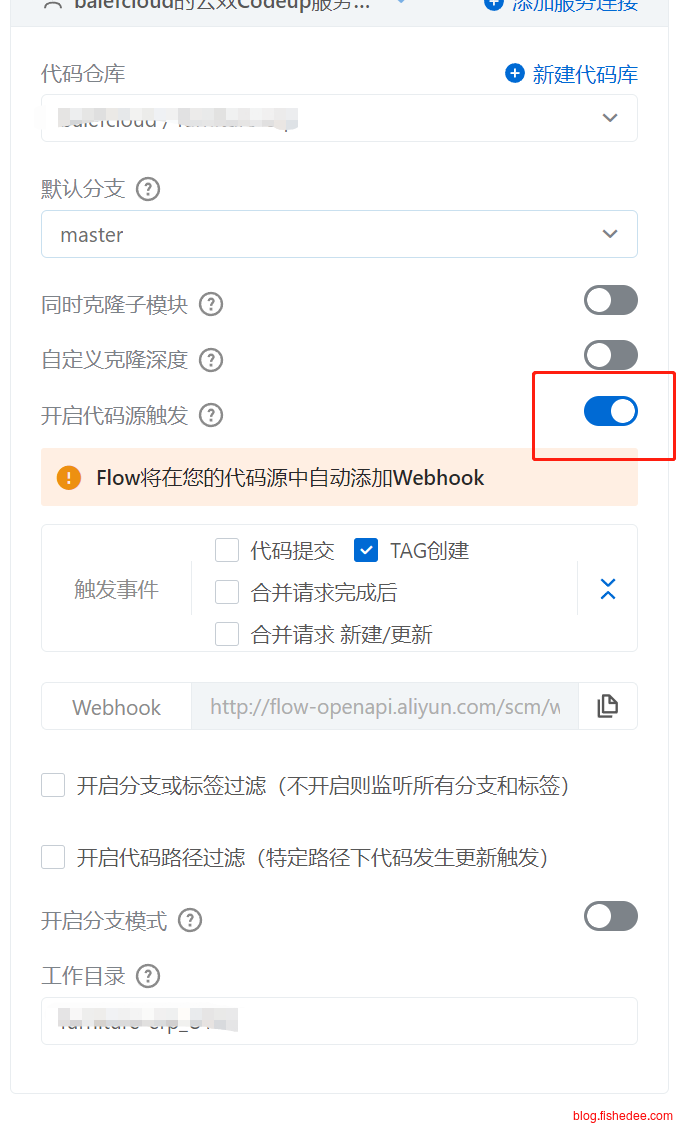
注意,我们要在流水线最左边的地方设置触发源,而不是控制台的顶部设置触发源。我们的计划流程是这样的:
- 开发组在master或者dev等分支进行开发
- 当需要发布版本的时候,运维填好发布特性和资料,并将当前的master分支设置add tag,推送到codeup中。
- Flow在收到关联Codeup的TAG创建事件以后,自动执行构建操作
- 经过人工审核以后,再进一步部署到具体的机器上
git tag -a V1.2 -m "xxx"
git push origin V1.2创建并推送TAG
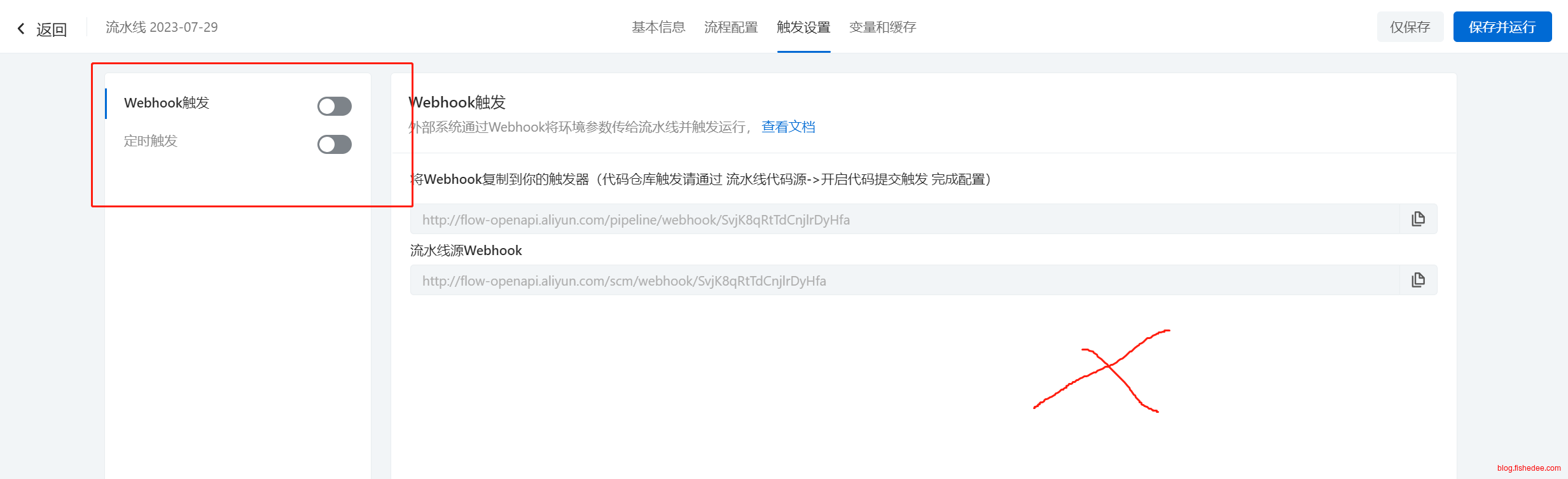
注意,在控制台上方配置Webhook触发是不对的。因为这样的触发方式,在流水线中是无法获取代码源是因为什么原因而触发流水线,流水线更无法获取触发的git tag是什么。
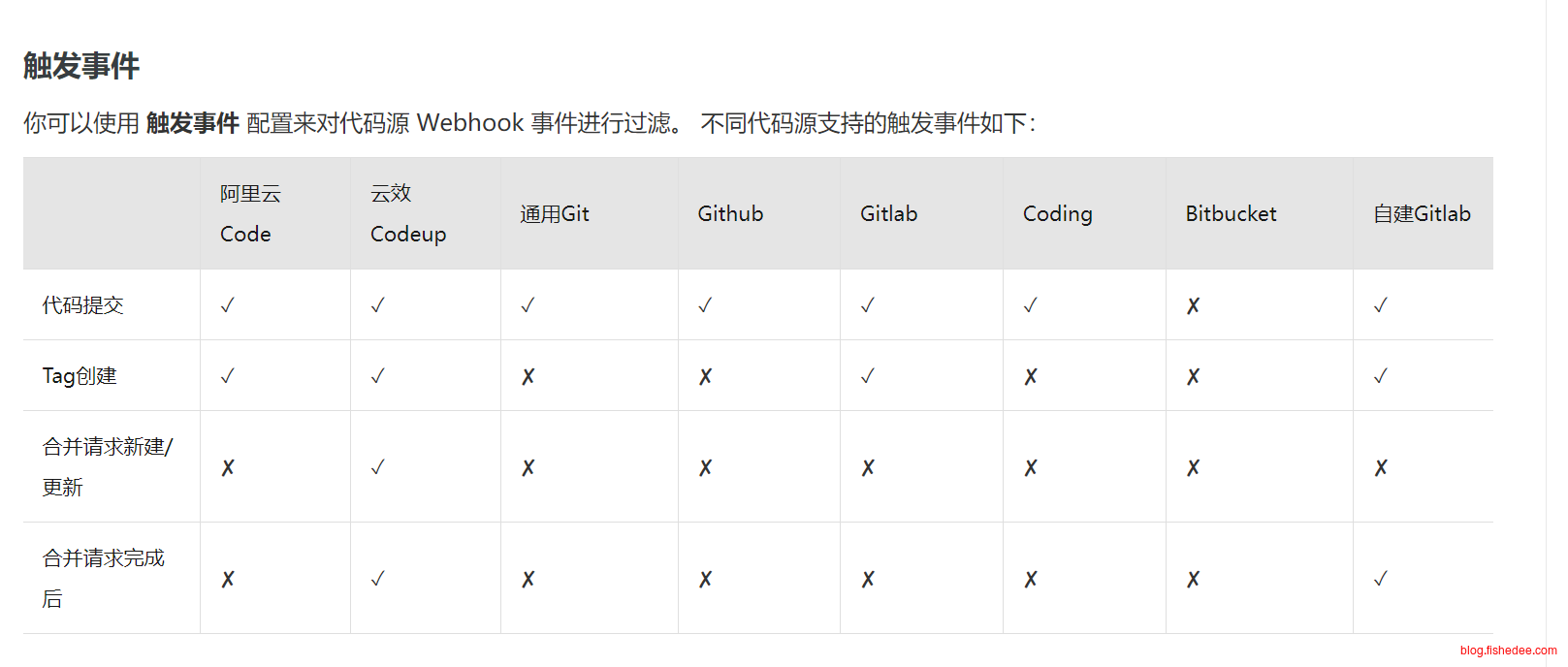
只有gitlab和阿里云仓库是支持Tag创建的时候,自动触发代码源,这意味着你只能选择以上的仓库。文档看这里
2.4 使用变量
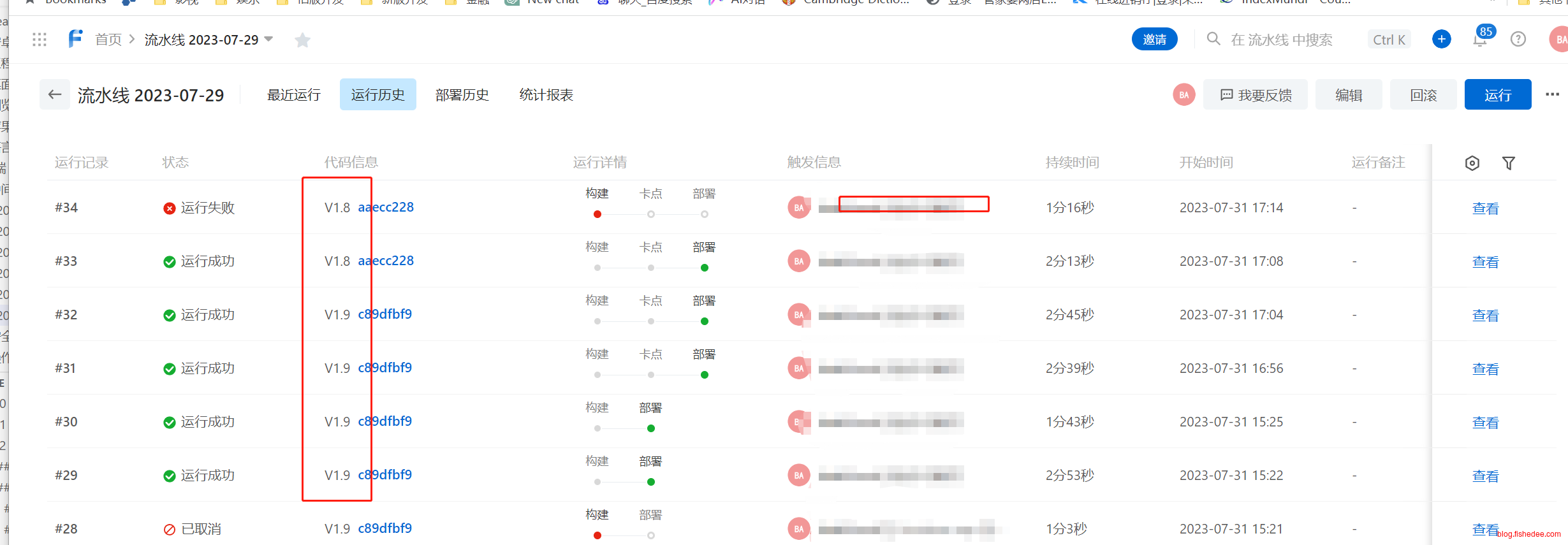
当代码源设置了以TAG的方式触发的时候,我们就会希望制品的名称,也是以版本号来记录的,这样,我们在历史记录里就能清楚看到,每次触发流水线的是具体哪个版本的代码。
实现方式很简单,使用内置变量名就可以了,看这里,在制品名称中输入${CI_COMMIT_REF_NAME}就可以了。
2.5 制品仓库
构建的时候,产生的制品,有两个常见的地方:
- 云效公共存储空间,存储文件名的方式是,流水线ID + 文件名。优点是,可以实现多流水线共享数据的地方。缺点是以流水线为ID为依据,相同代码版本TAG的文件竟然能覆盖。
- Packages私有制品仓库,储存文件名的方式是,文件名 + 版本号。优点是,相同代码版本TAG的文件不能覆盖,不能删除,保证研发流程信息可回溯。缺点是,无法在多流水线中共享数据。
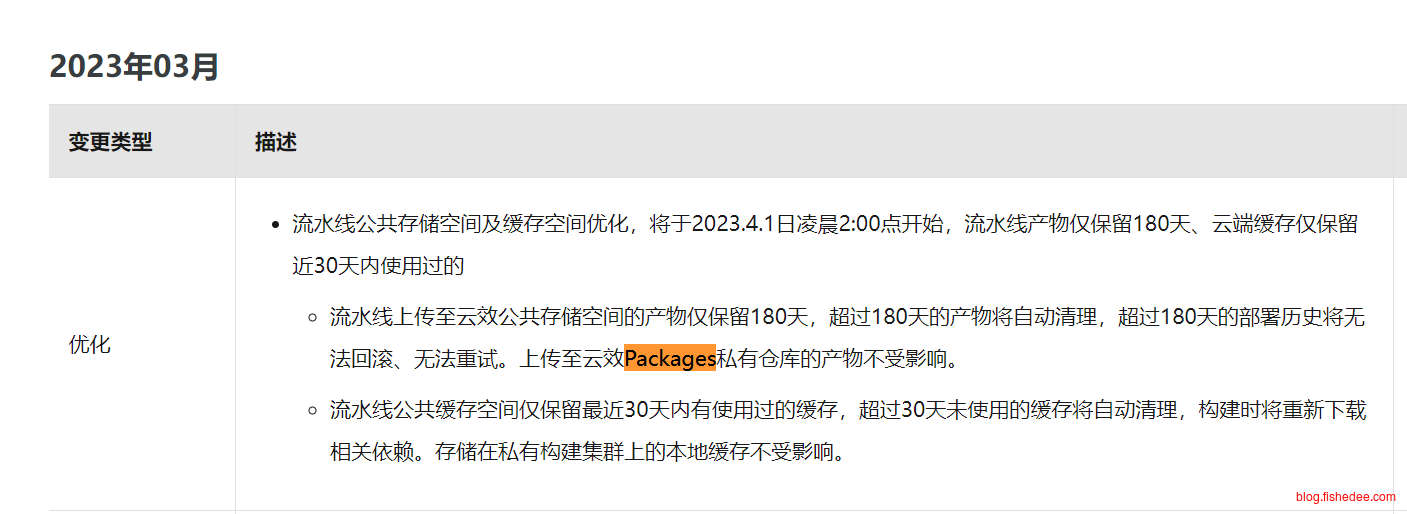
另外,云效公共存储空间与Packages私有制品仓库的寿命也不一样
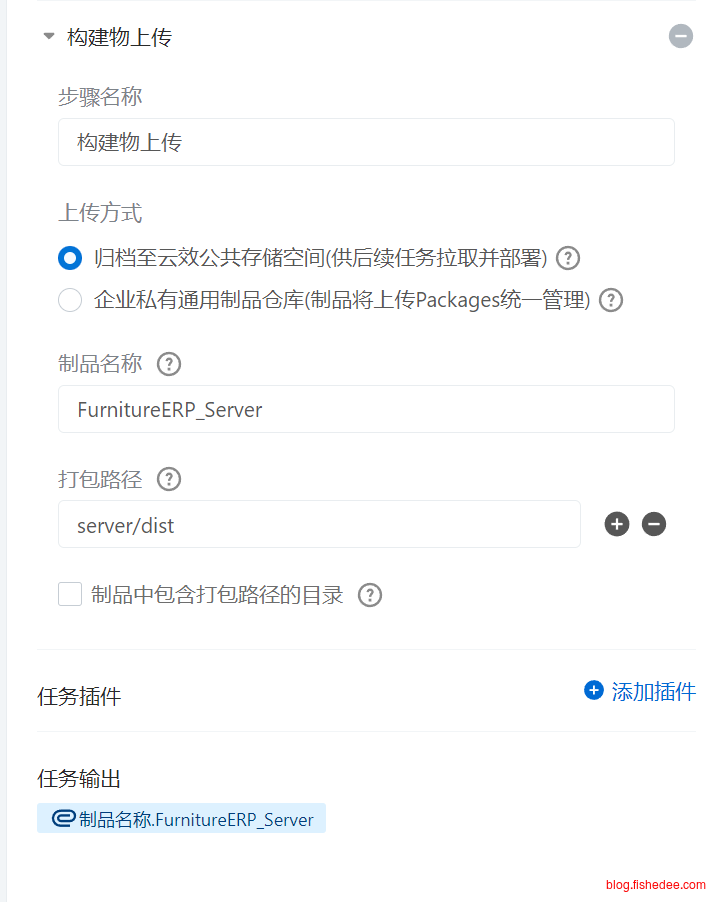
云效公共存储空间最为简单,有一个名称就行,它适合存放流水线的中间产物。
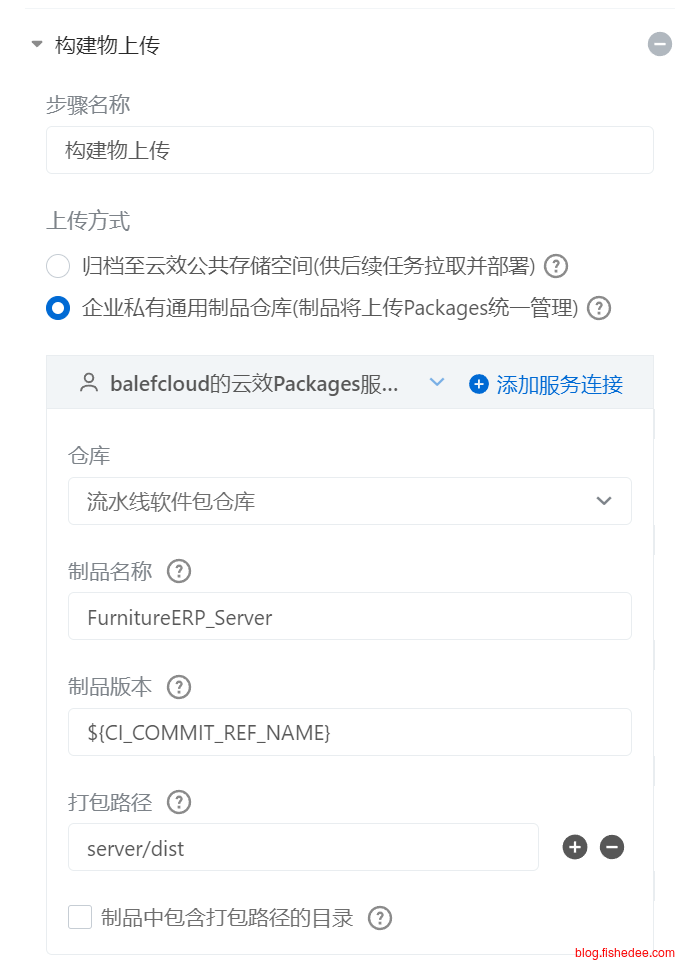
Packages私有仓库,则需要名称和版本号,它更适合存放流水线的最终产物。
2.6 流水线完成通知
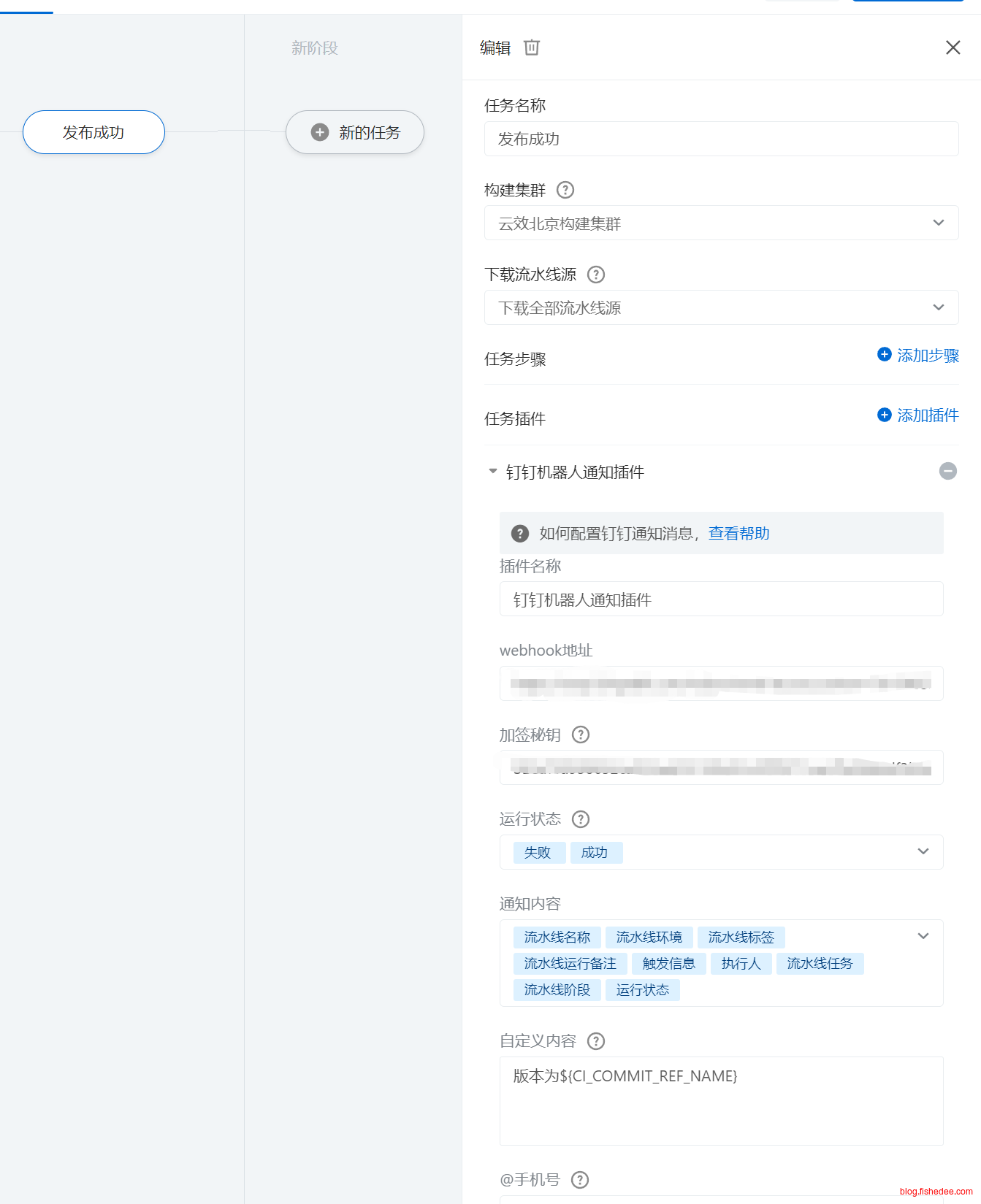
在流水线完成以后,我们希望能进行钉钉群的通知,这个的话需要三个参数:
- 钉钉群的机器人Webhook地址
- 钉钉群的机器人的加密钥匙
- 自定义内容
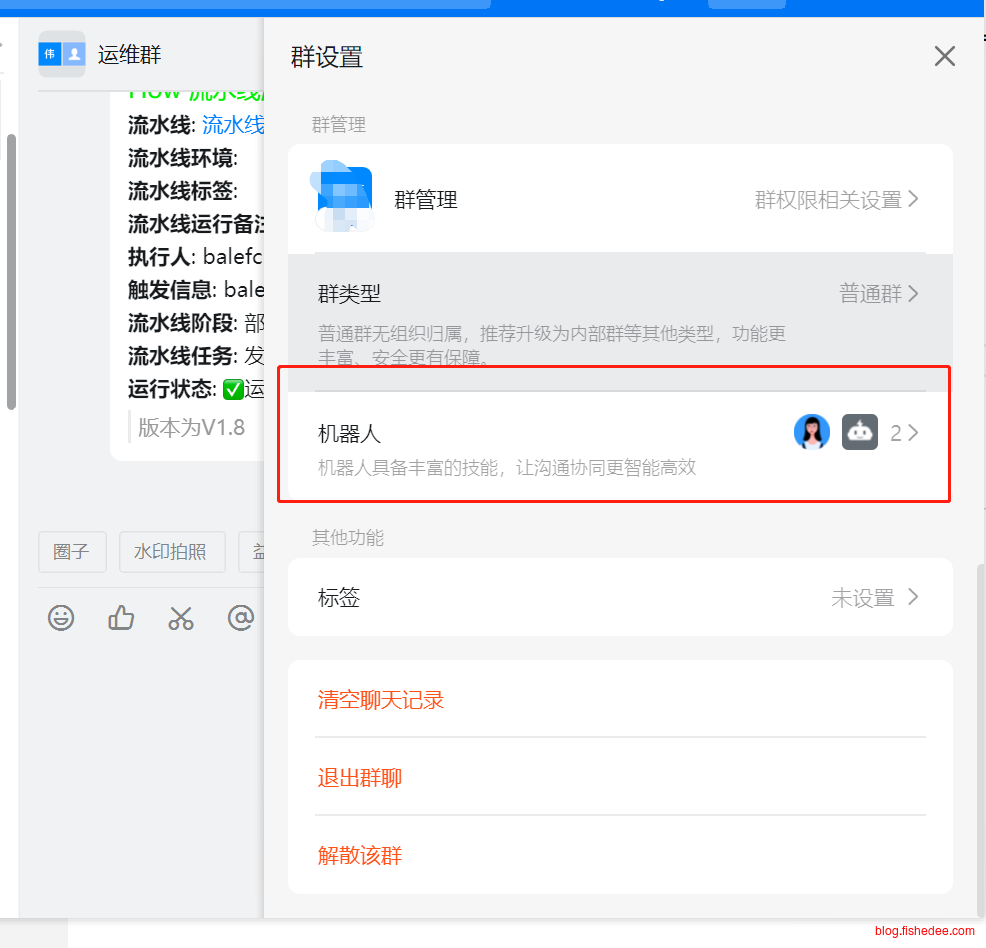
在电脑的钉钉上,打开群,点击右上角的设置,选择“机器人”
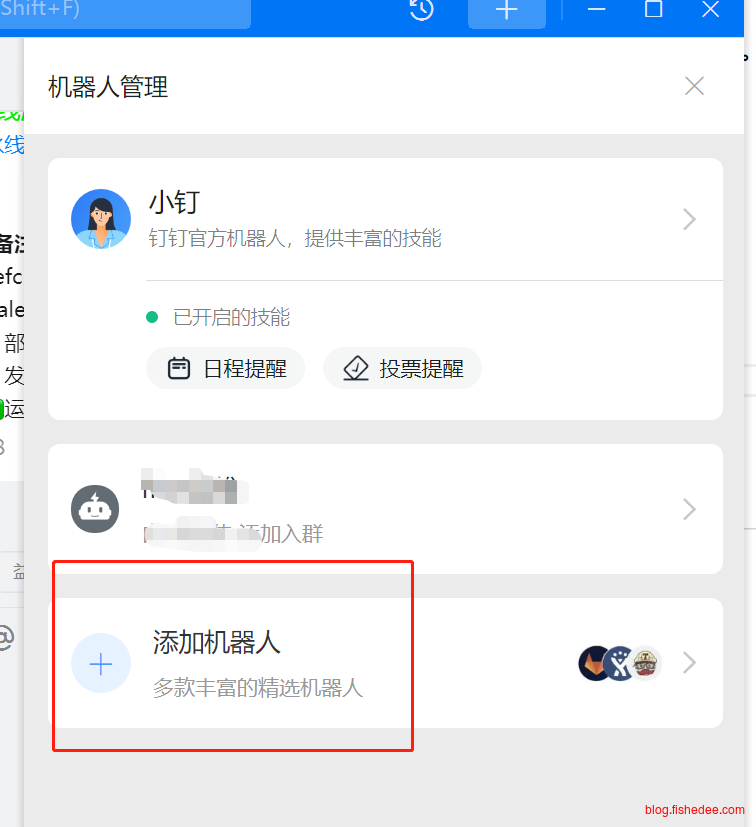
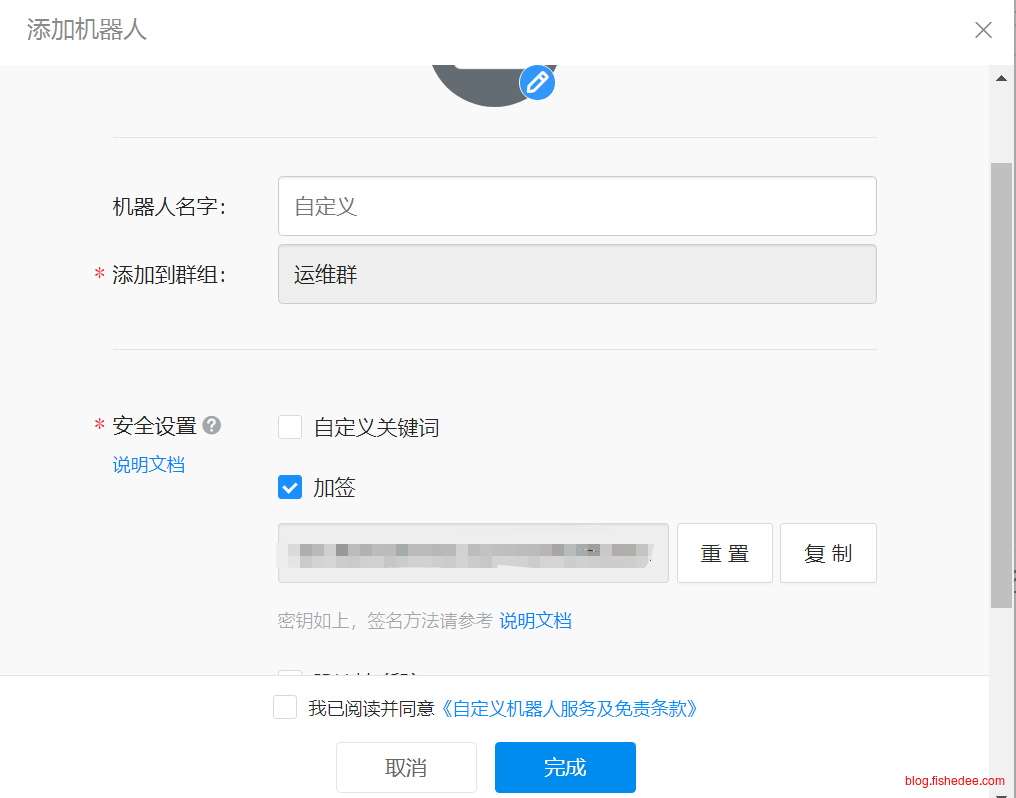
选择“添加机器人”,自定义Webhook,选择“加密”的安全方式,最终就能得到机器人的信息了。
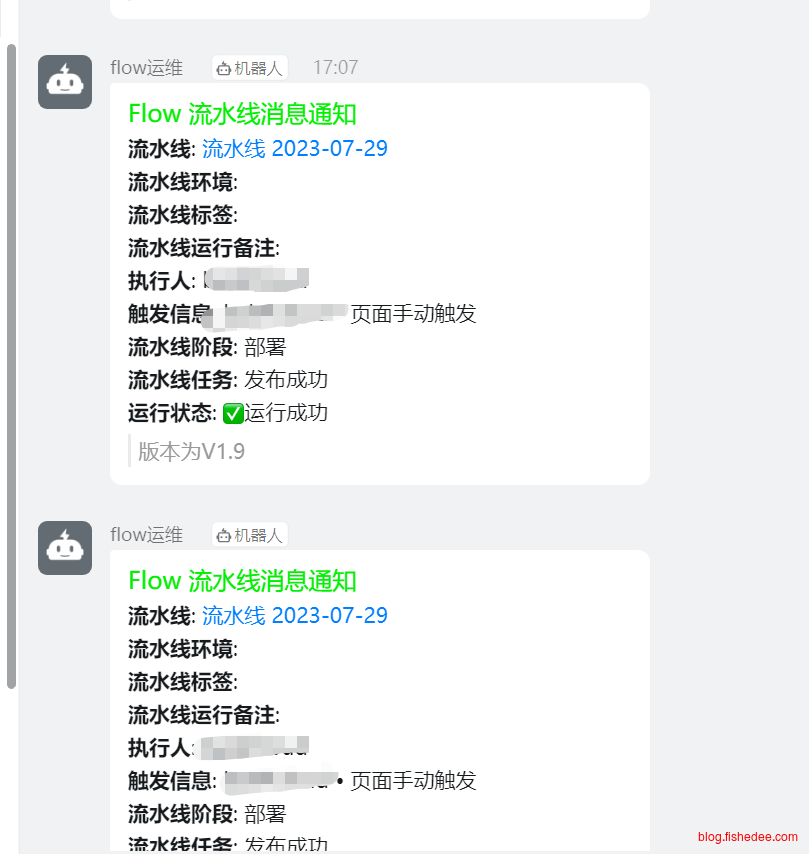
最终效果比较好,我们能随时得到通知
2.7 历史与回滚
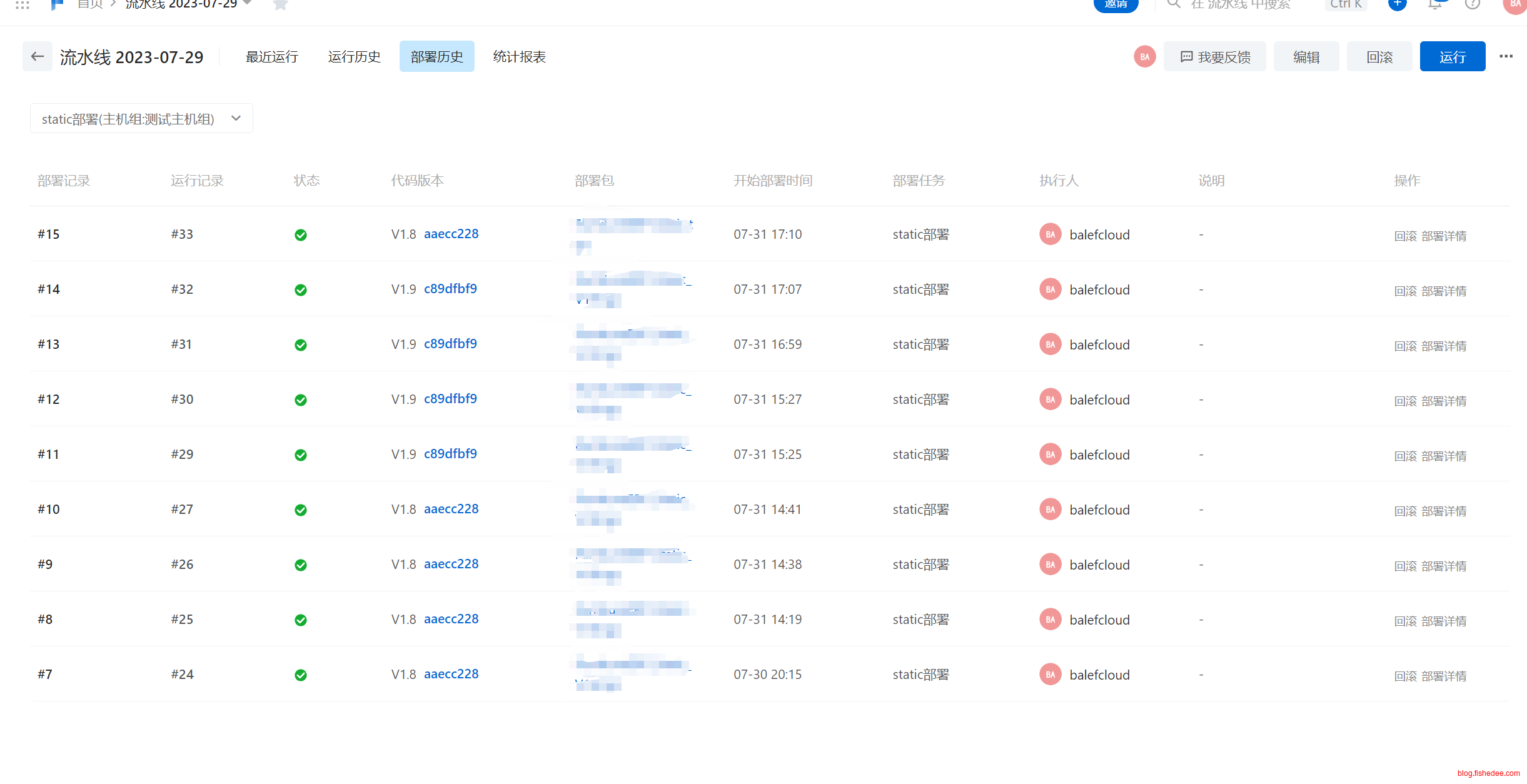
流水线的右上角有“部署历史”,我们可以选择部署包,来进行版本回滚,相当方便。
3 制品
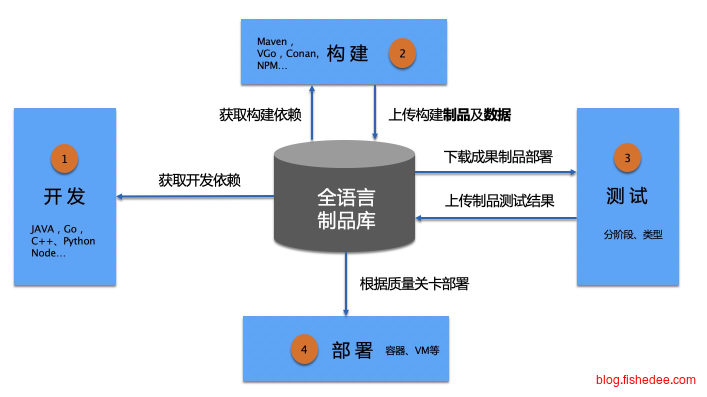
制品有两个主要用处:
- 存储流水线的部署品,一般放在“通用制品仓库”
- 存储公司内部所用的私有库,例如是私有Maven仓库和私有Npm仓库。大幅减少了需要自己部署私有Maven和私有Npm仓库的麻烦。
在流水线中,已经讲述了“通用制品仓库”的用法,就不再啰嗦了,这里主要讲私有库的使用。
3.1 私有Maven仓库
为了保证上传自己的库代码到私有Maven仓库不被搜索,需要在上传以后,搜索一下这里
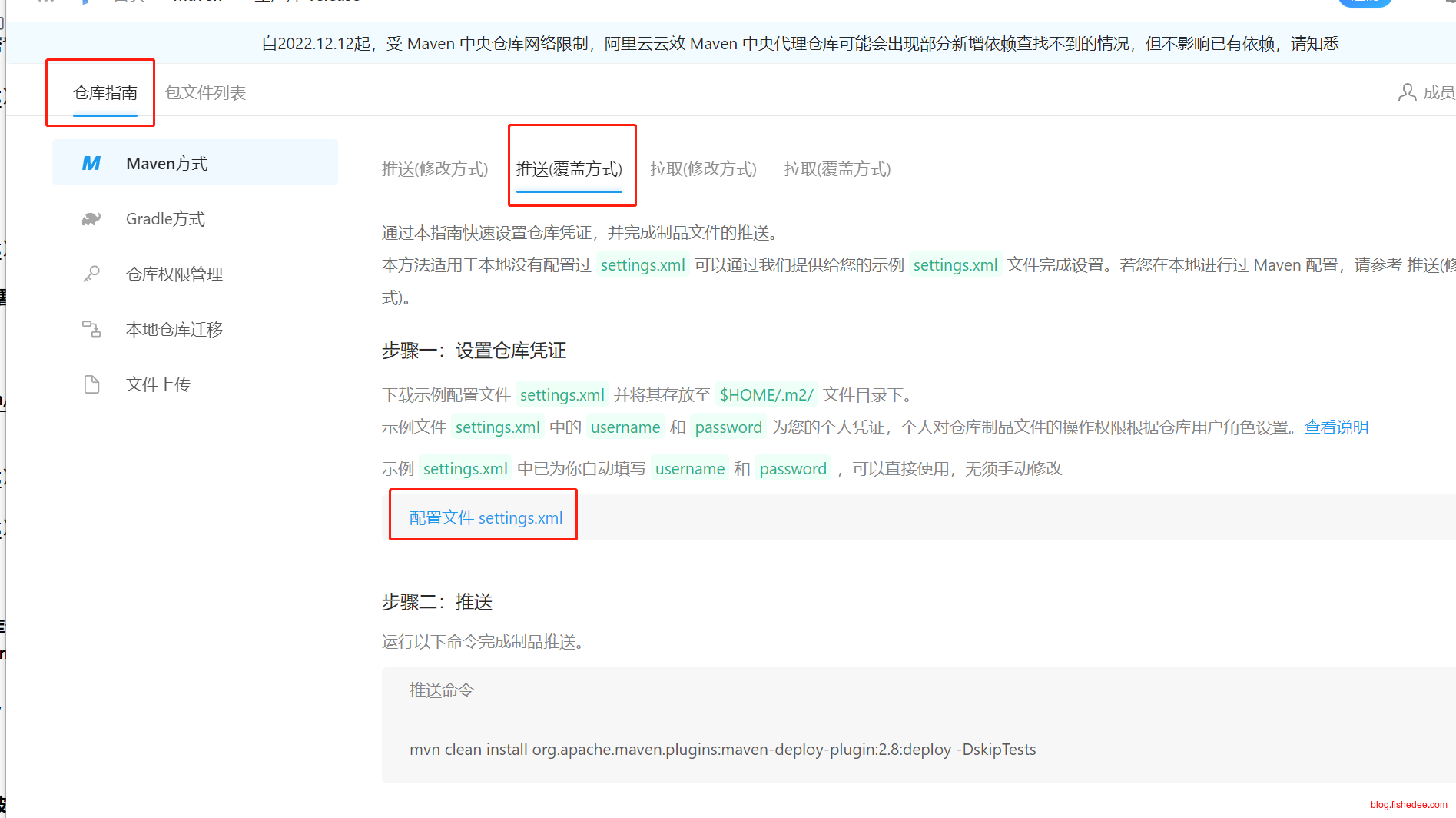
用法相当简单,在Maven仓库里面,点击“仓库指南”,再点击“推送(覆盖方式)”。下载好settings.xml
~/.m2/settings.xml
/Users/xxx/.m2/settings.xml下载好的settings.xml包含了阿里云用户的在Maven的账号和密码,直接覆盖现有的setttings.xml文件就可以了。
3.1.1 上传私有库
mvn clean install org.apache.maven.plugins:maven-deploy-plugin:2.8:deploy -DskipTests一条命令,直接部署到阿里云私有仓库
<groupId>com.example.xxxx</groupId>
<artifactId>xxxx</artifactId>
<version>1.0</version><groupId>com.example.xxxx</groupId>
<artifactId>xxxx</artifactId>
<version>1.0-SNAPSHOT</version>如果库代码的定义中,version字段有SNAPSHOT就推送到Snapshot 库,否则就推送到Release库,比较简单。
3.1.2 使用私有库
<dependencies>
<dependency>
<groupId>[GROUP_ID]</groupId>
<artifactId>[ARTIFACT_ID]</artifactId>
<version>[VERSION]</version>
</dependency>
</dependencies>使用的时候,直接写包就可以了,也很简单。
- 本文作者: fishedee
- 版权声明: 本博客所有文章均采用 CC BY-NC-SA 3.0 CN 许可协议,转载必须注明出处!